The bug that took down Reddit
On June 30, 2012, Reddit went down for over an hour.
So did LinkedIn and Mozilla. So did Yelp, Foursquare, StumbleUpon, and Gawker. Airline reservation systems collapsed; Qantas and Virgin Australia did manual check-in at airport gates for an hour, with delays across Qantas’s Australian network.[1]
The cause wasn’t a hack, a deploy, or a hardware failure. It was an extra second.
At precisely 23:59:60 UTC — a timestamp most date libraries don’t even believe is valid — the clocks on millions of Linux servers added a leap second to keep up with the slowing rotation of the Earth. And a lot of Java applications running on those servers started spinning at 100% CPU.
This is a story about how time is more complicated than it looks, why your code might have the same latent bug, and how Meta — after watching the industry trip over this twice — publicly argued for removing leap seconds entirely, and in the same year international standards bodies voted to phase them out.
The second that shouldn’t exist
To see why a leap second crashes computers, you have to know what it actually is.
Time, it turns out, has two definitions.
Atomic time is the rate at which a cesium-133 atom oscillates — exactly 9,192,631,770 cycles per second.[2] It’s an extraordinarily precise reference, because every cesium atom in the universe oscillates at the same rate. Since 1967, this is the official definition of the second.
Astronomical time is the rate at which Earth rotates. Earth is a lumpy ball with sloshing oceans, a flowing mantle, and rebounding glaciers — and it doesn’t rotate at a constant rate. Tides slow it by about 1.7 milliseconds per century on average. Earthquakes shave off microseconds — the 2011 Tōhoku quake is estimated to have shortened the day by about 1.8 µs.[3] Mass redistribution from melting ice nudges it the other way.
So which is “real” time? Depends on what you mean. A second of atomic time is a precise, unchanging quantity. A second of astronomical time means “1/86,400 of however long Earth’s rotation is taking right now.”
For most of human history, civil time was astronomical time — not by choice, but because it was the only available reference. Sundials, mechanical clocks, time zones: all calibrated to the sun. Atomic clocks didn’t exist yet.
After 1972, we ran on a hybrid called UTC. UTC ticks at the atomic rate, but periodically inserts an extra second — a leap second — to stay within 0.9 seconds of where Earth’s rotation says we should be. The leap second is the seam between the two definitions of time.
In normal UTC, a minute has 60 seconds, numbered 0 through 59. During a positive leap second, a minute has 61, going 23:59:58 → 23:59:59 → 23:59:60 → 00:00:00.
That extra second has been added 27 times since 1972.[4] Several of those have caused public software incidents. Many more probably caused private ones that never made the news.
What actually broke
The Linux kernel has two subsystems that need to agree on what time it is.
The timekeeping subsystem is the source of CLOCK_REALTIME — the wall clock, the thing your system’s date command reads.
From userspace, querying it looks like this:
#include <time.h>
struct timespec ts;
clock_gettime(CLOCK_REALTIME, &ts);
// ts.tv_sec = seconds since 1970-01-01 UTC
// ts.tv_nsec = nanoseconds within that secondThat single syscall reads the kernel’s wall-clock state.
The other system is the high-resolution timer, or the hrtimer subsystem. It’s part of the Linux kernel that sits on top of a hardware timer. Modern CPUs have a free-running counter that can be programmed to fire an interrupt when it reaches X. These counters tick at a fixed frequency, so the OS can convert a counter to time and vice-versa.
struct timespec mono;
clock_gettime(CLOCK_MONOTONIC, &mono);
// mono.tv_sec = seconds since boot (unspecified epoch, but stable)
// mono.tv_nsec = nanoseconds within that secondThe high-resolution timer is a layer on top that keeps all pending deadlines in a sorted structure such as a red-black tree. When a thread asks “wake me in 50 milliseconds” — e.g. Thread.sleep(50) — hrtimer inserts that deadline in the tree. It then looks at the earliest deadline and programs the hardware timer to fire at exactly that count. When the interrupt fires, the kernel wakes the thread waiting on it, removes it from the tree, then programs the hardware for the next earliest deadline.
So there’s no loop and no periodic polling.
However, while Thread.sleep(50) is a relative duration, the JVM didn’t pass “50ms from now” to the kernel. Instead, it passed an absolute wall-clock deadline. Internally, the JVM used pthread_cond_timedwait, which, by default, takes an absolute CLOCK_REALTIME deadline. So under the hood it would be something like:
clock_gettime(CLOCK_REALTIME, &now); // ask wall clock
deadline_wall = now + 50ms; // arithmetic in wall time
pthread_cond_timedwait(..., &deadline_wall);You may wonder, if the kernel uses hrtimer with interrupts, how can it take a wall-clock time as a parameter? For performance reasons, hrtimer doesn’t ask the timekeeping subsystem for the wall clock on every operation. It caches a translation between the clocks — something like “wall time 23:59:59.500 corresponds to monotonic tick 100,500,000,000 nanoseconds since boot.” Any wall-clock deadline gets converted to monotonic via the cache, then compared against a hardware tick counter — fast and cheap.
In June 2012, when Linux processed the leap second, it updated the timekeeping struct but didn’t refresh hrtimer’s cached translation. So when the wall clock stepped back from 23:59:59.999 to 23:59:59.000, the cache still thought wall 23:59:59.500 mapped to monotonic 100,500,000,000 — but the actual monotonic counter had ticked forward through the leap step by another full second of real time, to roughly 101,500,000,000. The cache was stale.
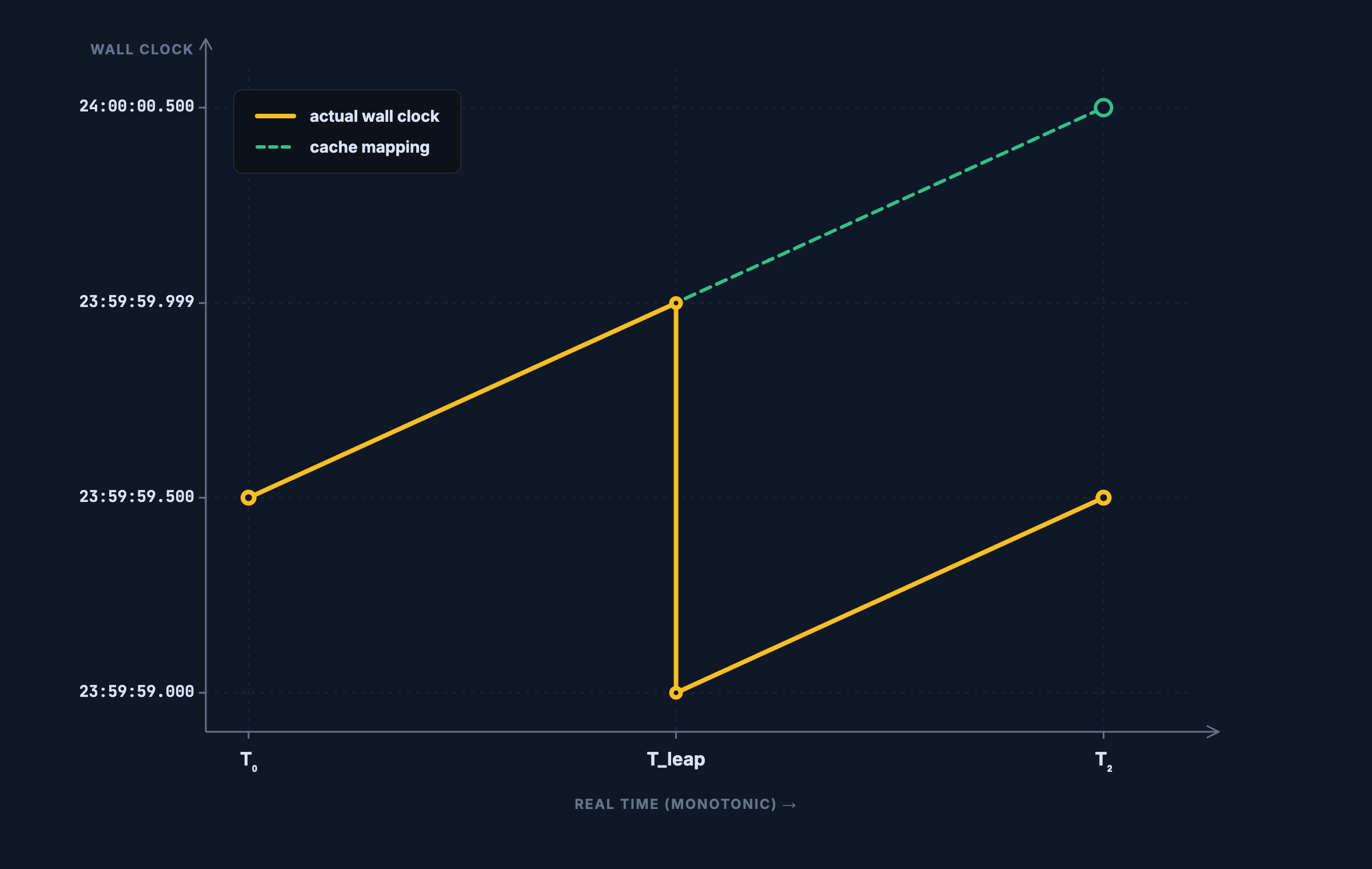
Some time later, a Java thread called Object.wait(50). The wall time was back at 23:59:59.500. The JVM target: wall 23:59:59.550. The kernel translated through the stale cache and got a monotonic target of 100,550,000,000 — but the actual monotonic counter was now 101,500,000,000. The deadline was already roughly 1 second in the past, so the kernel thinks: “deadline met, wake the thread.” The Java code, like most threading code, was in a wait-loop:
synchronized (lock) {
while (!ready) {
lock.wait(50); // wait up to 50ms, then re-check
}
proceed();
}The thread woke up, found the condition still not satisfied, and called Object.wait(50) immediately. Same translation through the same stale cache resulted in the instant return each time. Tens of thousands of iterations per second, per thread. The pattern only stopped when something forced the kernel to refresh the cache. Java was the loudest casualty because the JVM is heavy on timed waits, but the underlying kernel timer/futex paths affected many runtimes the same way.
Cassandra, a Java database, typically runs hundreds of threads per node doing this kind of wait. On affected machines, CPUs went from idle to pinned, and stayed there until the underlying timer state was reset.
The quickest fix was shared on Hacker News by an engineer trying things at random:
date -s "$(date)"Setting the date to its own current value, as a side effect, called the function the kernel had skipped. The cache refreshed and spinning stopped. The fix spread by tweet ahead of vendor patches; Red Hat shipped a kernel update a few days later.[5]
The pattern repeats
Four and a half years later, on December 31, 2016, the same physical event hit again. This time, one of the casualties was Cloudflare. Their custom DNS server, written in Go, had this line:
start := time.Now()
result, err := upstream.Resolve(query)
rtt := time.Now().Sub(start)Looks fine. Capture a timestamp before a DNS query, capture another after, subtract. You get the round-trip time.
Except time.Now() in Go, at the time, returned a wall-clock value. When the leap second hit, Linux handled it by stepping the wall clock back by one second. Any RTT measurement that straddled the leap-second boundary came out as roughly negative one second.
The code passed those negative values into Go’s rand.Int63n() — which RRDNS used for weighted resolver selection — and rand.Int63n() promptly panicked because the argument was negative. According to Cloudflare’s post-mortem, around 0.2% of DNS queries failed before the fix rolled out worldwide several hours later.[6]
So, we have two different incidents with different language, different layer of the stack, and different code. It’s the same wrong assumption underneath:
The code assumed time only goes forward.
That assumption shows up everywhere code touches time:
- Subtract two timestamps and expect a non-negative result.
- Set a deadline for the future (cache TTL, session expiry, retry-after header) and assume the timestamp will be in the past when it expires.
- Treat intervals as physical durations.
A surprising amount of clock arithmetic quietly trusts that wall-clock time is monotonic. It often isn’t.
You don’t need a leap second to hit this.
Quartz crystals inside servers drift constantly — by tens of microseconds per second. NTP — the Network Time Protocol — is what continuously corrects that drift, pulling local clocks back toward a reference. Most corrections are tiny. But every now and then, NTP decides the drift has gotten too big and “steps” the wall clock — jumping it to the right value, sometimes backward by a few hundred milliseconds.
Every backward step is a small leap-second-style discontinuity. Same bug class, smaller blast radius. Most NTP steps are too small for anything to crash on. But it’s the same code path that broke Cloudflare’s DNS — it doesn’t take a leap second to trip it.
How languages caught up
The Go team had been working on this since well before the Cloudflare incident — a 2015 proposal to add monotonic-time semantics. Go 1.9 shipped that fix in late 2017.[7] They didn’t change the API — time.Now() still returns a time.Time, Sub() still returns a Duration. They changed what’s inside a time.Time.
Now every value can carry two readings: a wall-clock reading for display, and a monotonic-clock reading for arithmetic. When you subtract two of them, Go transparently uses the monotonic one if both are present. The wall clock can step backward, jump forward, do whatever the leap second wants — the interval calculation stays sane, provided neither value has been serialized or reconstructed in a way that drops the monotonic reading.
Rust took a different approach with separate types. Instant::now() for measuring elapsed time, SystemTime::now() for displaying it, and the compiler refuses to let you confuse them.
These are two different bets on how to prevent the same bug. The distinction itself isn’t new — Python’s time.monotonic(), Java’s System.nanoTime(), and Rust’s Instant all predate the Cloudflare incident — but it’s still easy to reach for wall-clock APIs by default and not realize you’ve done it. That’s the main lesson: even when the language gives you the right primitive, you have to use it on purpose.
The workaround era
While Go was being patched, much of the industry settled on a workaround called smearing. Instead of inserting a discrete leap second, you slow your clock down by a tiny amount over many hours, so that by the time the leap second is officially inserted, your clock is already a second behind, and most applications never see a discontinuity.
Google smears over 24 hours, linearly.[8] Meta smears over 17 hours, quadratically.[9] AWS does its own thing.
Smearing helps — but it creates a new problem. During the smear window, every smearing fleet is on a slightly different clock than every other smearing fleet, and every smearing fleet is on a different clock than the non-smearing world. For 17 to 24 hours per leap event, the global internet runs on multiple active definitions of “what time it is right now.” There hasn’t actually been a leap second since the one that hit Cloudflare — Earth has been spinning slightly faster than expected. If the trend continues, the next leap event might actually be a negative leap second — skipping 23:59:59 instead of inserting 23:59:60. That has never happened in UTC’s history, and the failure mode (wall-clock jumping forward, not back) has never been tested at scale. If a positive leap second ever comes, the smear schemes are probably good enough now to absorb it for most workloads — but a negative one is uncharted.
It’s a band-aid on a band-aid.
Killing the second
In 2022, Meta published a blog post arguing that leap seconds shouldn’t exist.[9] The argument was simple. Civil time was tied to Earth’s rotation in 1972 because navigation depended on it: pre-GPS sailors converted star sightings into a ship’s location using Earth’s exact rotation angle, and the math broke if civil time drifted from astronomical time. Astronomers had similar requirements. Civilian and commercial navigation has long since moved off sextants. GPS time itself doesn’t insert leap seconds; receivers translate to UTC by applying a stored offset, but the underlying GPS scale runs continuously. Most modern systems don’t actually use Earth’s rotation as a time reference — but every leap second still risks tripping software across the industry.
Later that year, the General Conference on Weights and Measures passed Resolution 4: by no later than 2035, the allowed gap between UTC and Earth’s rotation will be widened far enough that leap-second corrections become rare — the goal language is to “ensure the continuity of UTC for at least a century” without an insertion.[10] So leap seconds aren’t being abolished outright; they’re being pushed out to roughly once-per-century events instead of once every year or two.
UTC will, for the first time in its history, be allowed to drift visibly away from the position of the sun. Over centuries, civil time will fall behind astronomical time by minutes. Sunrise apps and astronomy software will compensate by referencing UT1 — the same value astronomers already use for precise telescope pointing. Nobody will notice the drift in their lifetime.
In exchange: machines tick continuously, without the synchronized fault-injection event the industry has been bracing for every couple of years.
In parallel to the lobbying, Meta also built an internal clock API called fbclock[11] that returns time as a range (earliest, latest) instead of a single number — letting applications coordinate across machines without expensive consensus protocols. CERN’s White Rabbit[12] takes a different extreme: bidirectional fiber on a single wavelength to measure path asymmetry directly, used in particle accelerators for sub-nanosecond precision. Both are stories for another post.
What this means for your code
When you measure an interval, reach for a monotonic clock — time.monotonic() in Python, process.hrtime.bigint() in Node, Instant::now() in Rust, System.nanoTime() in Java, std::chrono::steady_clock::now() in C++. Save the wall clock for absolute times: log entries, scheduled events, displaying time to a human.
Be careful with timestamps that have crossed a process boundary. A Go time.Time value, for example, loses its monotonic reading the moment it’s serialized to JSON, written to a database, or sent over RPC; subtracting two such values is wall-clock arithmetic and can come out negative.
This isn’t a once-a-decade leap-second concern. NTP corrections, manual clock changes, and VM hibernation step the wall clock backward in routine operation. If you’ve ever seen a duration come out negative or impossibly large in production, it was likely a wall-clock subtraction, not a measurement bug.
The high-risk spots are wherever you do timestamp arithmetic: latency tracking, rate limiters, exponential backoff, retry-after calculations. Worth a pass through your code.
Reddit’s outage didn’t happen because of a bug in Reddit. It happened because layers of the stack underneath them had quietly assumed that time goes forward. Most of the time, it does. Once in a while, it doesn’t.
Sources
[1] The Register, “Leap second bug cripples Linux servers at airlines, Reddit, LinkedIn” (July 2012)
[2] BIPM, SI definition of the second — cesium-133 hyperfine transition, 9,192,631,770 Hz
[3] NASA JPL, “Japan Quake May Have Shortened Earth Days, Moved Axis” — length-of-day analysis following the 2011 Tōhoku earthquake
[4] IERS Bulletin C — leap second announcements, International Earth Rotation and Reference Systems Service
[5] Linux kernel commit by John Stultz, July 2012, fixing the clock_was_set() / hrtimer leap-second livelock; the contemporary Hacker News thread documents the date -s workaround spreading
[6] Cloudflare blog, “How and why the leap second affected Cloudflare DNS” (Jan 2017)
[7] Go 1.9 release notes; Go proposal #12914 by Russ Cox, “Monotonic Elapsed Time Measurements in Go”
[8] Google Public NTP — Leap Smear for the current 24-hour linear smear; the original 2011 Google blog post for the announcement
[9] Meta engineering, “It’s time to leave the leap second in the past” (July 2022) — documents the 17-hour quadratic smear and Meta’s case for retiring leap seconds. The 2025 PTP-specific post covers leap-second handling under PTP.
[10] CGPM Resolution 4, 27th General Conference on Weights and Measures, BIPM (November 2022)
[11] Meta engineering, “How Precision Time Protocol is being deployed at Meta” (Nov 2022) — fbclock and Window of Uncertainty
[12] White Rabbit Project (Wikipedia) — CERN’s sub-nanosecond clock distribution protocol; uses bidirectional fiber to measure path asymmetry directly
Enjoyed this post?
I send an email every two weeks about computer science and software engineering. No fluff, no hype — just the mechanism behind the things we use every day.