Blockchain, Block, and Merkle Tree
In the previous post, we talked about hash functions and transactions. We also explained what transaction inputs and transaction outputs are and how to spend coins.
In this post, you are going to learn what is:
- A block
- A block header
- A block hash and compute it from the block header
- A Merkle tree and implement an algorithm to construct it from transactions
What is a blockchain?
A blockchain is a distributed list (chain) of blocks of transactions spread across the entire network of nodes. The SHA-256 hash of the block header identifies each block. What’s interesting about the blockchain is that each block header contains a reference to the previous block, also known as the parent block. The sequence of blocks linking their parents goes all the way back to the first node, known as the genesis block.
I don’t know if the following story about sharks and DNAs is scientifically accurate. Nevertheless, it should serve as a good metaphor for the blockchain.
Let’s think of a hammerhead shark. Female hammerhead sharks can reproduce without a male. Each shark has DNA that uniquely identifies it. Children inherit DNA from their parents, and in this case, a baby hammerhead shark inherits its DNA from its mother. The DNA of every shark carries information about all of its ancestors. If a wizard somehow magically changed the mother’s DNA, then the DNA of the baby shark would have to change as well to keep the natural order.
Similarly, the reference to the parent block inside the block header affects the current block’s hash. If the parent’s identity changes, then the child’s identity changes, which causes a chain reaction, so the grandchild’s identity changes. The process is repeated until all of the descendant’s identities are changed.
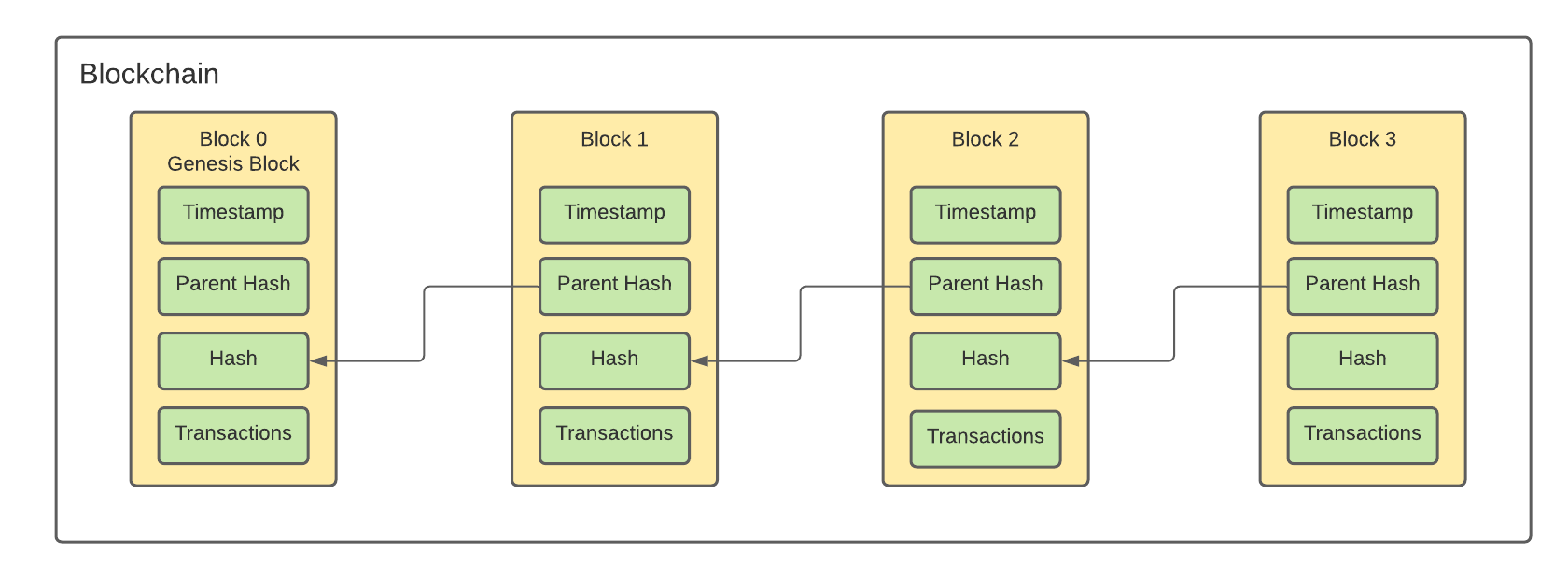
The above diagram shows the relationship among blocks in the blockchain.
This property ensures that once a block has many generations following it, it cannot be changed without forcing a recalculation of all subsequent blocks. As the chain gets longer, it becomes harder to change, making the blockchain’s deep history effectively immutable. This property is a crucial feature of Bitcoin’s security.
Each block has exactly one parent. However, a block may have more than one child, which may happen when two different miners find a new block simultaneously. Therefore, a blockchain is effectively a tree of blocks (not a list), where only one path from the root to a leaf represents an active chain. We will discuss the difference between the active chain and other chains when we talk about the blockchain’s consensus algorithm.
What are blocks and block headers?
Let’s look more closely into the block and block header’s anatomy to better understand how blockchain works.
A block consists of a block header and a list of transactions.
Each block has a unique identifier which is made by hashing the block header twice through the SHA-256. The resulting message digest is the block header hash. However, in practice, it is called the block hash.
The block hash identifies the block uniquely and unambiguously, and implicitly all of its ancestors.
Similar to what we did with transaction IDs, we will introduce a new type to represent the block hash, even though we could use Sha256 directly.
// learncoin/src/block.rs
#[derive(Hash, Ord, PartialOrd, Eq, PartialEq, Debug, Copy, Clone)]
pub struct BlockHash(Sha256);
#[derive(Debug, Clone)]
pub struct Block {
// Block hash that is equivalent to `header.hash()`.
// It's convenient to store it here, rather than having to get it via block header each time.
id: BlockHash,
header: BlockHeader,
// A list of transactions included in this block.
transactions: Vec<Transaction>,
}Block header consists of the following:
- Version – A version number to track software/protocol upgrades.
- Previous block hash – The hash of the parent block.
- Merkle Root – A hash of the root of the Merkle tree built on top of this block’s transactions. Don’t worry, we’ll talk more about it in the next paragraph.
- Timestamp – The approximate creation time of this block (as seconds from the Unix Epoch)
- Difficulty Target – The difficulty target used in the Proof-of-Work algorithm to find the block.
- Nonce – A counter used for the Proof-of-Work algorithm.
The mining process and validation require timestamp, difficulty target, and nonce in their implementations.
// learncoin/src/block.rs
/// Block header represents the metadata of the block associated with it.
#[derive(Debug, Clone)]
pub struct BlockHeader {
// Version number ignored.
// A reference to the hash of the previous (parent) block in the chain.
previous_block_hash: BlockHash,
// A hash of the root of the Merkle tree of this block's transactions.
merkle_root: MerkleHash,
// The approximate creation time of this block (seconds from Unix Epoch).
timestamp: u64,
// The Proof-of-Work algorithm difficulty target for this block.
difficulty_target: u32,
// A counter used for the Proof-of-Work algorithm.
nonce: u32,
}It’s common to produce a hash from the block header, so let’s introduce a function to do that. In reality, we would serialize the block header in little-endian format as follows:
| Field name | Size |
|---|---|
| Version | 4 bytes |
| Previous block hash | 32 bytes |
| Merkle Root | 32 bytes |
| Timestamp | 8 bytes |
| Difficulty target | 4 bytes |
| Nonce | 4 bytes |
The above table shows the encoding format of the block header. Note that the timestamp is 8 bytes, but the Bitcoin uses 4 bytes and it runs out in 2016.
The encoding ensures that the hash is computed based on the values that are both language and platform-independent. However, similar to what we did to compute the transaction’s hash, we concatenate all values as strings, which is easier and allows us to focus more on the blockchain concepts rather than encoding.
// learncoin/src/block.rs
impl BlockHeader {
// ...
pub fn hash(&self) -> BlockHash {
let data = format!(
"{}{}{}{}{}",
self.previous_block_hash,
self.merkle_root,
self.timestamp,
self.difficulty_target,
self.nonce
);
// Hash the block header twice.
let first_hash = Sha256::digest(data.as_bytes());
let second_hash = Sha256::digest(first_hash.as_slice());
BlockHash::new(second_hash)
}
}What is a Merkle tree?
We have been using something called Merkle root, but we haven’t defined it yet.
Each block in the blockchain contains a summary of all the transactions in the block. This summary is what we call a Merkle root.
A merkle root is the root node of a Merkle tree, a binary tree data structure used to efficiently summarize and verify the integrity of large sets of data. When N data elements are hashed and summarized in a Merkle tree, you can check if the tree includes a data element with at most 2* log_2 (N) calculations. We will use Merkle root to validate blocks later in the series.
How to construct a Merkle tree?
A merkle tree is constructed by recursively hashing pairs of nodes until there is only one hash left, the Merkle root:
- The leaves of the Merkle tree are hashes of transactions. These hashes are the initial level 0.
- Construct a parent by iterating over pairs of children nodes from left to right in the current level. Produce a parent value by concatenating the children’s values.
- Go to the next level. Repeat the above step until the current level has only one node left.
- If there is an odd number of nodes at some height (except when there’s only one node left), then the last node in the level is duplicated.
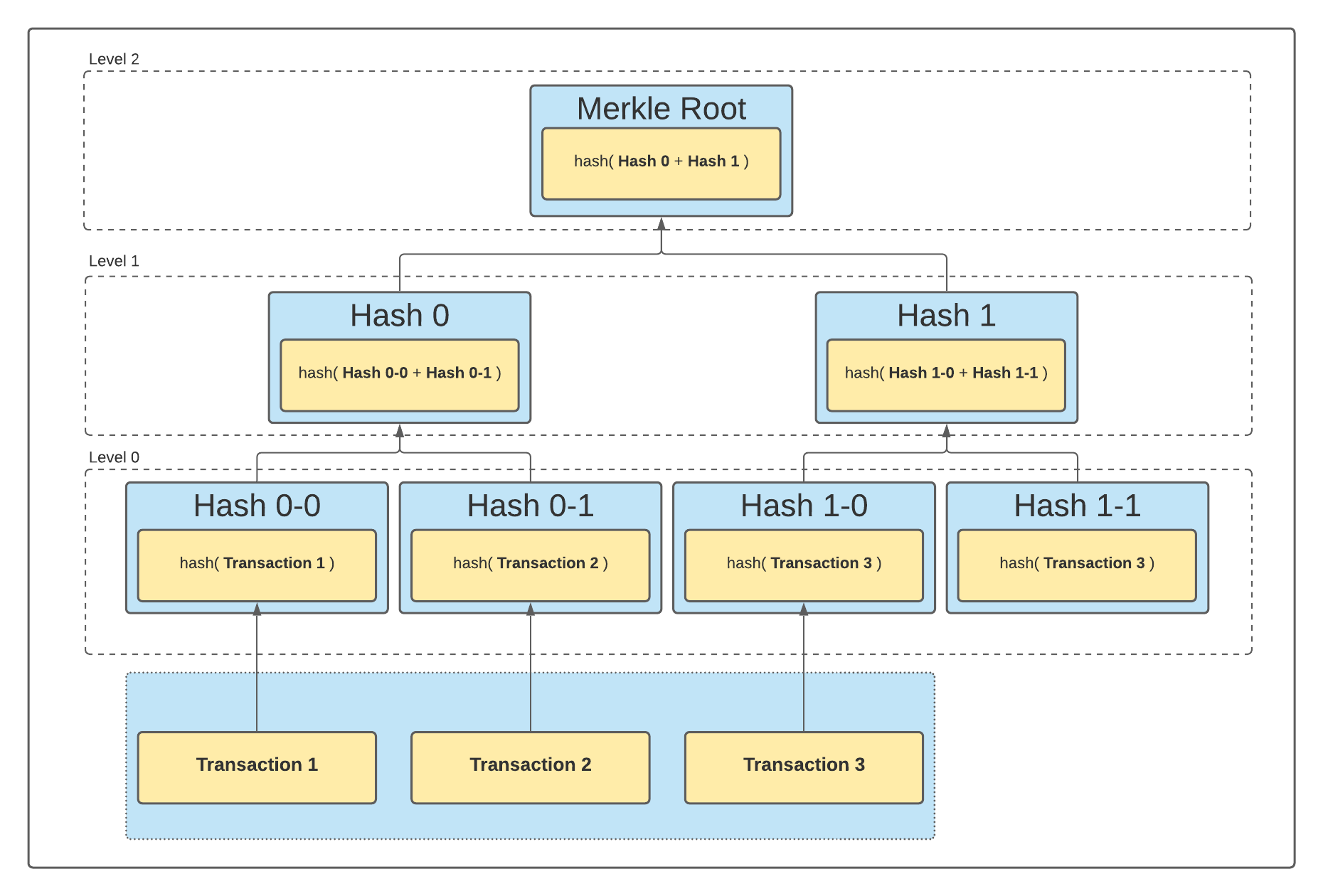
The above diagram shows how to construct a Merkle Tree for three transactions. Note that level 0 has only three values initially, so we duplicate the last one (Transaction 3) to get an even number of nodes on that level.
Implement a Merkle Tree
Let’s implement the algorithm to construct a Merkle tree for the given list of transactions. We will compute the Merkle root and throw away the intermediate results because we don’t need the full Merkle tree at the moment.
// learncoin/src/merkle_tree.rs
use crate::{Sha256, Transaction};
use std::fmt::{Display, Formatter};
/// Represents a SHA-256 hash of a Merkle tree node.
#[derive(Debug, Copy, Clone)]
pub struct MerkleHash(Sha256);
pub struct MerkleTree;
impl MerkleTree {
pub fn merkle_root_from_transactions(transactions: &Vec<Transaction>) -> MerkleHash {
let leaves = transactions
.iter()
.map(|tx| tx.id().as_slice())
.collect::<Vec<&[u8]>>();
Self::merkle_root(&leaves)
}
pub fn merkle_root(leaves: &Vec<&[u8]>) -> MerkleHash {
assert!(!leaves.is_empty());
let mut current_level_hashes = leaves
.iter()
.map(|leaf| Sha256::digest(*leaf))
.collect::<Vec<Sha256>>();
while current_level_hashes.len() != 1 {
if current_level_hashes.len() % 2 == 1 {
// If a level has an odd number of nodes, duplicate the last node.
current_level_hashes.push(current_level_hashes.last().unwrap().clone());
}
let mut next_level_hashes = vec![];
for i in (0..current_level_hashes.len()).step_by(2) {
let lhs = current_level_hashes.get(i).unwrap();
let rhs = current_level_hashes.get(i + 1).unwrap();
// Concatenate children's hashes.
let mut concat = lhs.as_slice().iter().map(|x| *x).collect::<Vec<u8>>();
concat.extend_from_slice(rhs.as_slice());
// The concatenated hash is the value of the new parent node in the next level.
next_level_hashes.push(Sha256::digest(&concat))
}
current_level_hashes = next_level_hashes
}
// The first (and only) node is the root.
MerkleHash::new(current_level_hashes.into_iter().next().unwrap())
}
}Let me know if there’s anything unclear. The code implements the algorithm described in the previous paragraph.
Summary
This was a lot of code. Let’s summarize what we’ve done in this post.
- We have introduced block and block header.
- We have implemented an algorithm to find the Merkle root of a list of transactions.
- We have a better understanding of what information the blockchain tracks.
Here’s the full source code.
What’s next?
In the next post, we will talk about the proof of work algorithm and implement a miner.
Enjoyed this post?
I send an email every two weeks about computer science and software engineering. No fluff, no hype — just the mechanism behind the things we use every day.