Hash Functions and Transactions
In the previous post, we created a starting project with a CLI tool, a placeholder for the server that connects to its peers, and a client to issue RPCs to a server.
In this part of the series, we will explain the following:
- What is a cryptocurrency
- What is a cryptographic hash function
- Anatomy of the transaction, transaction inputs and transaction outputs
What is a cryptocurrency?
We’ll try to explain the cryptocurrency by using Bitcoin as a reference. It is a collection of concepts and technologies that form a basis for the digital money ecosystem. Bitcoins, which represent a currency for digital money, store and transmit value among its network participants.
Users can use Bitcoin to do just about anything that traditional currencies can do. They can buy and sell goods, send money to others, etc. Unlike conventional currencies, Bitcoins are entirely virtual.
Imagine you’d like to spend a $50 bill. You can do that because you have physical access to the banknote, and you decide what to do with it. Users of Bitcoin have the keys to prove their ownership. These keys can sign a transaction to unlock the value and spend it by transferring it to a new owner. Therefore, whoever has the key can spend the money, so users should store the keys securely.
Bitcoin is a distributed, peer-to-peer system. As such, there is no central server that controls it. Bitcoins are created through “mining”, which is a process of finding a solution to a mathematical problem.
Bitcoin consists of:
- A decentralized peer-to-peer network which implements the Bitcoin protocol.
- A public transaction ledger, also known as the blockchain.
- A set of rules that each participant in the network uses to validate transactions.
- A mechanism for reaching a global decentralized consensus on the valid blockchain, known as the proof of work.
What is a cryptographic hash function?
A cryptographic hash function is an algorithm that maps data of arbitrary size (often called messages) to a bit array of a fixed size (called a hash value, hash, or message digest). It is a one-way function, which means it’s practically impossible to invert or reverse the computation.
Ideally, the only way to find a message that produces a given hash is to attempt a brute-force search of possible inputs to see if they produce a match. The proof of work algorithm relies on this important property.
When a pair of inputs map to the same value, we call it a hash collision.
In a nutshell, it represents a digital signature of the data.
Properties of a good cryptographic hash function
- It is deterministic, which means that the same input always results in the same hash.
- It is “quick” to compute the hash value for any given message.
- It is practically impossible to reverse the process, i.e., generate the input for the given hash value or part of the hash value.
- It is practically impossible to find two different messages with the same hash value.
- A small change to a message should change the hash value so that the new value appears utterly unrelated to the old one.
How is that different from a regular hash function?
A cryptographic hash function aims to guarantee several security properties, the most important one being that it’s “hard” to find hash collisions.
Non-cryptographic hash functions try to avoid hash collisions, but it’s not a hard requirement. In exchange for weaker guarantees, they are typically faster.
As such, all cryptographic hash functions are also hash functions, but not all hash functions are cryptographic hash functions.
SHA-256 is an example of a cryptographic hash function that is often used nowadays, and it’s a hash function used to build core concepts of the blockchain, as we will see in this blog post series.
An example of a broken cryptographic hash function is MD5 because it aims to provide security. However, it’s broken because there are flaws in the algorithm that allow the attacker to construct several messages with the same MD5 hash cheaply.
Note that regular hash functions cannot be broken because they never aimed to provide security in the first place.
Introduce an API for SHA-256 hash value
Make sure to add a dependency on the hex and sha2 libraries. We use the sha2 library to calculate the SHA-256 message digest and hex to display the result in the console. However, we will implement our SHA-256 algorithm later in the series.
If you are following the implementation in a different language, you should find the corresponding libraries online. These are very common, and most languages support them. Let me know in the comments if you run into any problems, and I’ll do my best to help you.
# learncoin/Cargo.toml
[dependencies]
...
hex = "0.4.3"
sha2 = "0.9.8"Let’s introduce an interface to represent the message digest of the SHA-256.
// learncoin/src/hash.rs
use sha2::Digest;
use std::fmt::{Display, Formatter};
const SHA256_BYTE_COUNT: usize = 32;
/// Sha-256 is a 256-bit array or 32 bytes.
/// It provides an API to display itself as a hex-encoded string and parse it from a hex-encoded string.
#[derive(Copy, Clone, Hash, Ord, PartialOrd, Eq, PartialEq)]
pub struct Sha256([u8; SHA256_BYTE_COUNT]);
impl Sha256 {
pub const fn from_raw(raw_bytes: [u8; SHA256_BYTE_COUNT]) -> Self {
Self(raw_bytes)
}
pub fn digest(data: &[u8]) -> Self {
unimplemented!()
}
pub fn as_slice(&self) -> &[u8] {
&self.0[..]
}
pub fn to_hex(&self) -> String {
unimplemented!()
}
pub fn from_hex(s: &str) -> Result<Self, String> {
unimplemented!()
}
}
Let’s first look at the digest API. It takes an arbitrary length array and produces a 256-bit array. To compute the message digest, we update the SHA object with our data, then finalize it.
We will discuss the update and finalize APIs when we implement our version of the algorithm. For now, it’s sufficient to know that the update allows us to apply the SHA-256 algorithm on the part of the data, which helps compute the hash of large objects that don’t fit in RAM, e.g., via streaming messages.
All cryptocurrency data fits easily in RAM, and the digest function is easier to use than the update + finalize combo.
// learncoin/src/hash.rs
impl Sha256 {
// ...
pub fn digest(data: &[u8]) -> Self {
let mut hasher = sha2::Sha256::new();
hasher.update(data);
let result = hasher.finalize();
assert_eq!(result.len(), SHA256_BYTE_COUNT);
let mut output = [0; SHA256_BYTE_COUNT];
for (i, byte) in result.iter().enumerate() {
output[i] = *byte;
}
Sha256::from_raw(output)
}
}Let’s also provide an API to represent SHA-256 as a hex-encoded string and parse it from a hex-encoded string.
// learncoin/src/hash.rs
impl Sha256 {
// ...
pub fn to_hex(&self) -> String {
hex::encode(self.as_slice())
}
}Converting SHA-256 to hex is trivial using the library. However, converting hex to SHA-256 is slightly more involved because we have to detect if the hash length is correct and the string is valid.
// learncoin/src/hash.rs
impl Sha256 {
// ...
pub fn from_hex(s: &str) -> Result<Self, String> {
match hex::decode(&s) {
Ok(bytes) => {
let mut sha = [0; SHA256_BYTE_COUNT];
if bytes.len() == SHA256_BYTE_COUNT {
for i in 0..SHA256_BYTE_COUNT {
sha[i] = *bytes.get(i).unwrap();
}
Ok(Sha256::from_raw(sha))
} else {
Err(format!(
"Invalid SHA-256 length. Expected: {} but got: {} in: {}",
SHA256_BYTE_COUNT,
bytes.len(),
s
))
}
}
Err(e) => Err(e.to_string()),
}
}
}Finally, let’s implement Display and Debug traits that ensure SHA-256 objects are printed as hex-encoded strings rather than a bunch of bytes.
// learncoin/src/hash.rs
impl Display for Sha256 {
fn fmt(&self, f: &mut Formatter<'_>) -> std::fmt::Result {
write!(f, "{}", self.to_hex())
}
}
impl Debug for Sha256 {
fn fmt(&self, f: &mut Formatter<'_>) -> std::fmt::Result {
// Implement Debug via Display.
write!(f, "{}", self)
}
}Great, you’ve done well! We have a better API to compute and represent SHA-256.
What is a transaction?
A transaction tells the network that the Bitcoin owner has authorized the transfer to another owner. The new owner can now spend the Bitcoin by creating another transaction, and so on.
Transactions consist of one or more inputs and one or more outputs. Transaction inputs are like withdrawals from the account, while transaction outputs are like deposits to the account.

The inputs and outputs do not necessarily add up to an equal value. Instead, the sum of outputs is smaller than the sum of inputs. The remainder is the transaction fee, which is paid to the miner, including the transaction. We’ll talk more about the mining process in later chapters.
The transaction also contains proof of ownership (as a digital signature) for each spent input. The proof ensures that only the owner can spend the money.
// learncoin/src/transaction.rs
#[derive(Debug, Clone)]
pub struct Transaction {
id: TransactionId,
inputs: Vec<TransactionInput>,
outputs: Vec<TransactionOutput>,
}Transaction ID
A transaction has an ID associated with the contents of the transaction. This ID is a result of applying the SHA-256 cryptographic hash function twice to its contents.
// learncoin/src/transaction.rs
/// A double SHA-256 hash of the transaction data.
#[derive(Debug, Hash, Eq, PartialEq, Copy, Clone)]
pub struct TransactionId(Sha256);Hopefully, there’s nothing odd here.
The transaction ID is SHA-256 message digest.
We could have used Sha256 directly, but I prefer to introduce separate types for different concepts, even when their underlying representation is precisely the same.
This approach ensures that we can’t accidentally use block hash, which is also a SHA-256 value, instead of the transaction ID.
Let’s compute the transaction ID. We will concatenate the string representations of all inputs and outputs to represent the transaction in bytes, then use its byte representation to compute the hash.
This is not exactly how the hashing of a transaction works in practice. However, we are skipping these details to focus on more interesting stuff. As a result, you may get a different value depending on what implementation you choose. Also, note that my implementation depends on how Rust represents strings in memory (UTF-8), so you may get different values in a different language.
We will use the same approach to get the hash for all of the objects. However, please let me know if this is something that you’d like me to talk about in one of the future blog posts.
// learncoin/src/transaction.rs
impl Transaction {
pub fn new(
inputs: Vec<TransactionInput>,
outputs: Vec<TransactionOutput>,
) -> Result<Self, String> {
let id = Self::hash_transaction_data(&inputs, &outputs);
let transaction = Self {
id,
inputs,
outputs,
};
Ok(transaction)
}
fn hash_transaction_data(
inputs: &Vec<TransactionInput>,
outputs: &Vec<TransactionOutput>,
) -> TransactionId {
let data = format!(
"{}{}",
inputs
.iter()
.map(TransactionInput::to_string)
.collect::<Vec<String>>()
.join(""),
outputs
.iter()
.map(TransactionOutput::to_string)
.collect::<Vec<String>>()
.join("")
);
let first_hash = Sha256::digest(data.as_bytes());
let second_hash = Sha256::digest(first_hash.as_slice());
TransactionId(second_hash)
}
}Transaction inputs and transaction outputs
Let’s say you have a 3. You must spend all of your 3 and returns $47 to you as a change.
Bitcoin works similarly.
Transaction outputs represent banknotes that we can spend, while transaction inputs tell the network which transaction outputs to spend.
Therefore, a transaction input references a transaction output to spend in the form of <transaction_id>:<transaction_output_index>.
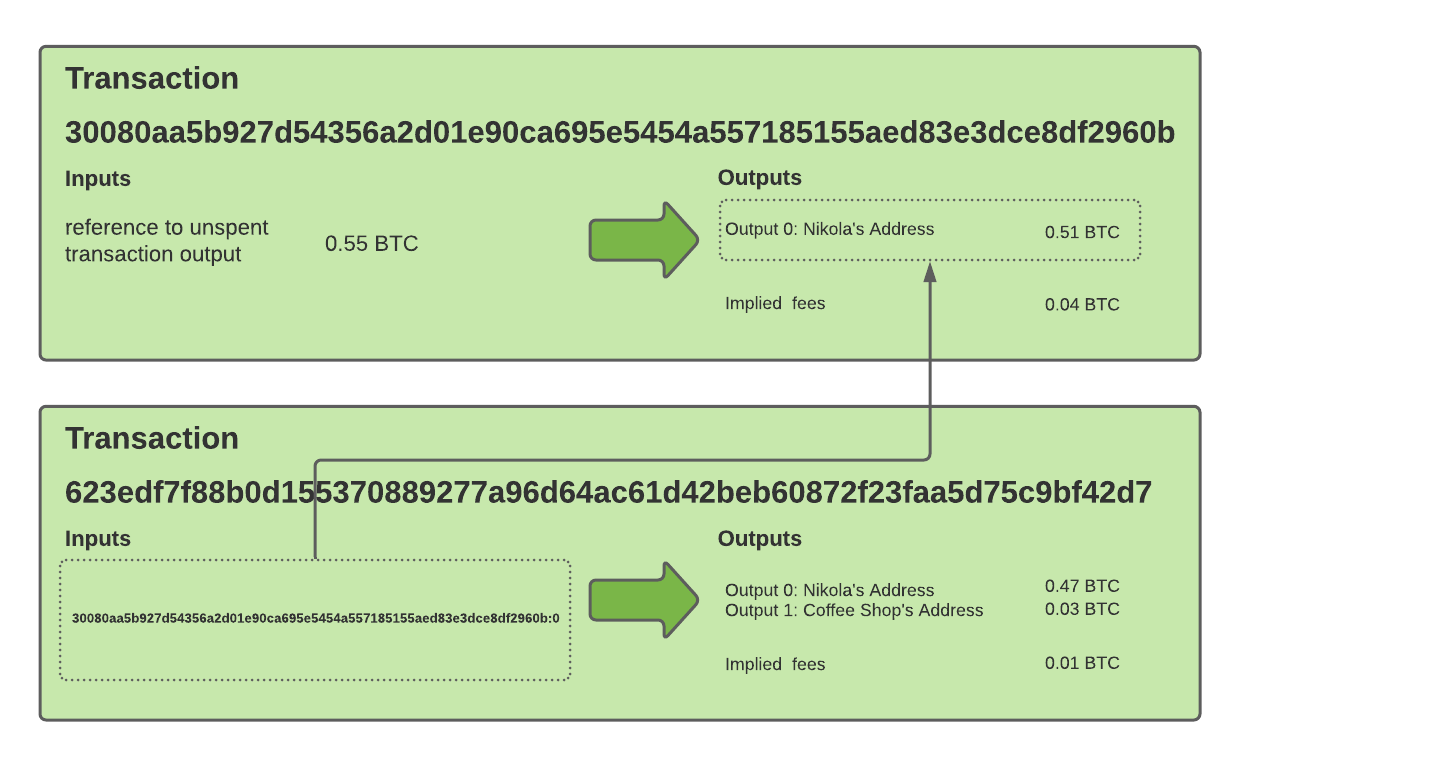
A diagrma above shows a transaction to purchase the coffee and get back the change.
Note that the whole transaction output must be spent in the same way we must give away the 3 and $47 in the above example.
You may be wondering if anyone can spend any transaction output, and if not, how is this problem solved?
When a transaction output is created, it is locked with a script (called locking script). The locking script represents a puzzle that a transaction input must solve to spend it. Therefore, apart from the reference to the transaction output, the transaction input includes the corresponding unlocking script too. This process is known as a pay-to-script-hash.
Bitcoin uses an approach where transaction outputs are locked with a public key in asymmetric cryptography, known as the Bitcoin address. This approach is known as a pay-to-pubkey hash. It allows the private key owner to spend the transaction output. We will implement a virtual machine to process these scripts and explain how they work in detail later in the series.
Furthermore, a transaction output can be spent at most once. Otherwise, that would lead to spending the same transaction output multiple times and eventually making Bitcoin worthless. While the malicious attacker may reference already spent transaction outputs, the network keeps track of all unspent transaction outputs (UTXOs) and validates the transaction before accepting it. Again, this is something that we will tackle when we implement validation.
When you see something like “an address 1BvBMSEYstWetqTFn5Au4m4GFg7xJaNVN2 has 1337 BTC”, it means that there are (potentially many) unspent transaction outputs locked with the public key that is the given address, and the sum of their amounts is 1337.
We will implement all of the above eventually, but for now, we will keep the locking and the unlocking script empty.
// learncoin/src/transaction.rs
/// The index of the transaction output.
#[derive(Debug, Eq, PartialEq, Clone)]
pub struct OutputIndex(i32);
pub struct LockingScript {
// TODO: Left empty until we implement validation.
}
pub struct UnlockingScript {
// TODO: Left empty until we implement validation.
}
#[derive(Debug, Clone)]
pub struct TransactionInput {
// 32 bytes. A pointer to the transaction containing the UTXO to be spent.
utxo_id: TransactionId,
// 4 bytes. The number of UTXO to be spent, the first one is 0.
output_index: OutputIndex,
// Transaction inputs must provide the unlocking script that is a solution to
// the locking script in the reference transaction output.
// This is required to implement validation.
unlocking_script: UnlockingScript,
}
#[derive(Debug, Clone)]
pub struct TransactionOutput {
locking_script: LockingScript,
amount: i64,
}Getting back the change
Every time we want to spend a transaction input, we must spend it as a whole. A typical transaction is to send part of the transaction input to the coffee shop and the change back to ourselves. If we forget to explicitly send the difference to ourselves, we may pay some lucky miner a lovely fee.
Summary
In this blog post, we’ve learned about the differences between cryptographic and regular hash functions and how to generate the transaction ID. Furthermore, we have a better understanding of transactions, transaction inputs, and transaction outputs.
Here’s the source code for this blog post.
What’s next?
In the next post, we will talk about the anatomy of the block and block header and how they form a distributed ledger called a blockchain.
Enjoyed this post?
I send an email every two weeks about computer science and software engineering. No fluff, no hype — just the mechanism behind the things we use every day.