The engineers who ship more do less
How do you make sure you actually finish things every week?
A lot of engineers spend time thinking about focus. They mute notifications, block time on their calendar, and try to reduce interruptions because context switching is hard.
All of that is useful. But I don’t think focus is the main problem most of the time.
The more common pattern is that Friday comes, and you have three important things that are all partway done. That progress has value, of course. And having a few things in progress at once is perfectly normal. I’m not saying every Friday should end with everything shipped. But a lot of the value is still locked up, because the hardest part often comes near the end: review, alignment, staging, rollout, follow-up. You were busy all week, but nothing quite crossed the line.
I used to struggle with this myself as an IC, and nowadays I see it as a manager too. Usually the issue is not effort. It’s that people plan around activity instead of finish lines, then keep changing the week as new things come up, and end up with too many threads open at once.
That’s what I want to talk about.
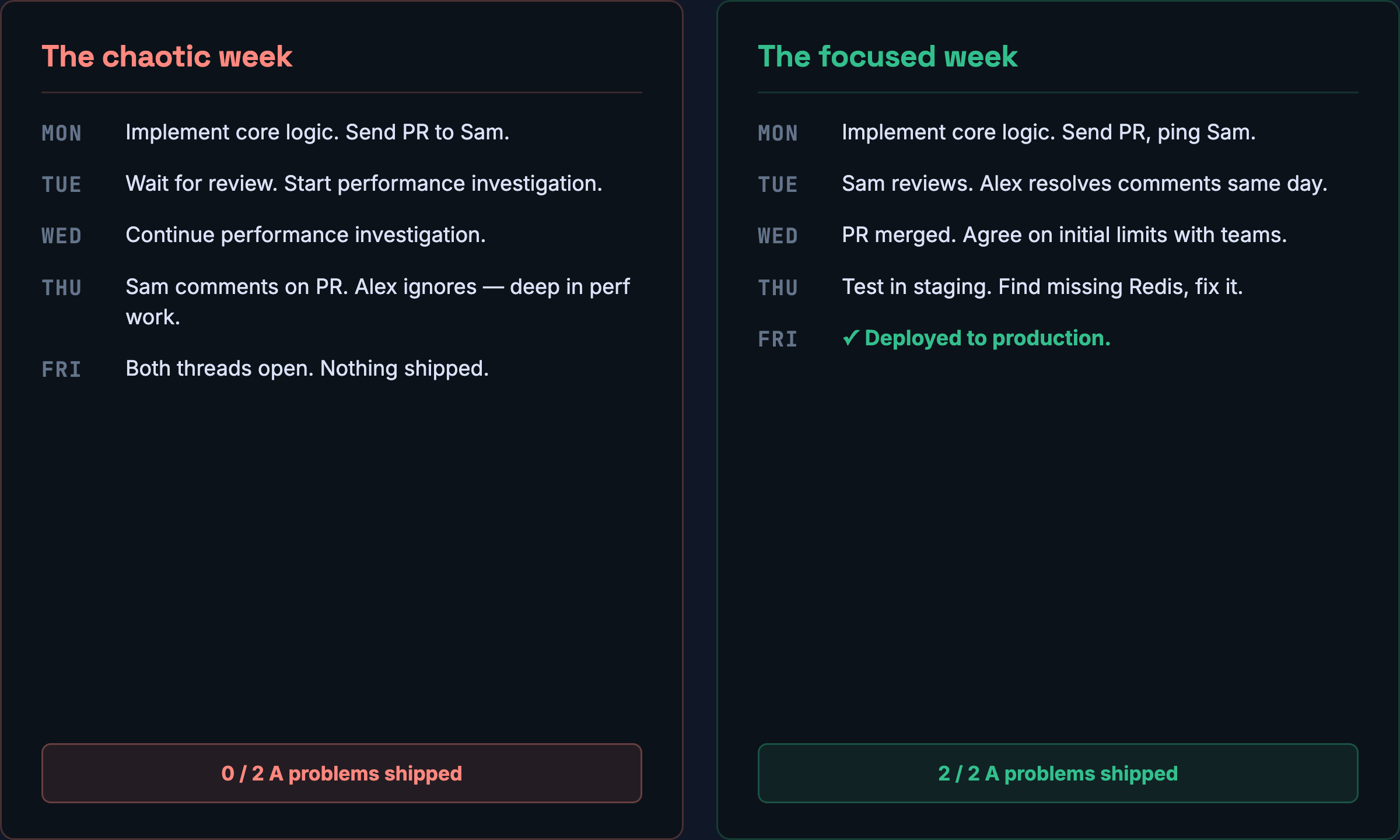
Example: Alex implements rate limiting
Let’s say Alex is asked to introduce rate limiting to her team’s internal REST API.
The higher-level goal is clear: roll out rate limiting safely in production.
Some parts of the situation are already decided for her. She’s not choosing them:
- On her team, production code needs one teammate’s review before it can be merged. In this case, Sam is the reviewer.
- Other teams use the API, so before turning rate limiting on, Alex needs to finalize the initial production limits with them.
- The feature has to be tested in staging before it goes to production.
So a simplified path to done looks like this:

Alex starts the week working on rate limiting. She finishes the core logic quickly and sends the PR to Sam by Monday EOD.
Now, to be clear, sending a PR can absolutely be a finish line. If the implementation itself is large enough, “PR ready for review” may be a perfectly reasonable goal for the week. But in this case, the work is close enough that getting it merged looks realistic. That makes it the more useful finish line.
Alex still needs to finalize the limits, but that feels straightforward, and she assumes she can do it while the PR is in review.
Then her manager mentions another issue: some part of the service has a performance problem affecting a customer.
This matters. But it isn’t necessarily “drop everything right now.” It’s just another thing that is now on Alex’s plate.
Since the rate-limiting work is waiting on review, Alex starts looking into the performance issue. She does some investigation, gets a few ideas, and starts working on a fix.
By Thursday, Sam leaves comments on the rate-limiting PR. Alex sees them, but by then she is already deep in the performance investigation and tells herself she’ll come back to the PR later.
By Friday, both threads are still in progress.
This is where people start to feel stressed. Not because having a queue of work is automatically bad, but because the priorities are now fuzzy. Every item feels important, every thread is unfinished, and it becomes hard to tell whether the week is actually going well.
Alex feels annoyed because if she had gotten the response sooner, she wouldn’t have to context switch. She did her part and sent the code for review — it’s on Sam now that it’s delayed.
When this happens, it’s usually some combination of these things:
- The weekly plan is vague, or it changes ad hoc based on whatever feels urgent
- The plan is written as activity, not finish lines
- There are too many open threads
- You get blocked on others and stop treating the work as yours
- The last 20% is uncomfortable, so it’s very easy to drift to something new
Focus on A problems
At the beginning of the week, don’t begin with tasks. Begin with facts and finish lines.
By facts I mean: what is already true this week? What commitments already exist? What approvals do you need? What dependencies do you have? Did any new input come in from your manager, customers, or incidents?
Then ask: given that starting point, what are the real finish lines for this week?
I call those A problems.
An A problem is not the whole project. It is the weekly finish line that matters now, has a clear end point, and is realistic to hit this week. Everything else is a B problem.
B problems can still be valuable. They just are not the things you want to accidentally let steal the week.
This is mostly useful when you actually have choices. If one thing is obviously the highest-priority thing to do, great, just do that. The A/B framing becomes useful when there are several plausible things you could work on and you need a way to stop treating all of them as equally urgent.
In Alex’s case, the overall project goal is “deploy rate limiting safely in production.” That is real, but it is too big to use as the weekly plan unless the work is already very close.
Better A problems for Alex’s week would be:
- Get the rate-limiting PR reviewed and merged
- Agree on the initial production limits with the teams using the API
Those are concrete. They matter now. They unlock the next steps: staging and deployment.
If both happen early enough, testing in staging or even deploying to production can become the next A problem, or a stretch goal for the same week.
The performance issue may still be important. But unless someone explicitly says “stop what you’re doing and work on this now,” it starts as a B problem for this week. Not because it has no value, but because if the value is roughly comparable, you should usually default to the work that is already in motion and closest to a real finish line.
And if you do end up switching to something else — because you’re waiting on review, or you hit a genuine blocker — switch back as soon as your A problem is unblocked. When Sam comments on Thursday, that’s the signal. The default move is to close the loop on rate limiting, not to tell yourself you’ll get to it later.
To choose your A problems, ask: what matters now? What is ambitious enough to move the project forward? And what has a real finish line that I can hit this week?
Also, if you can’t name the weekly finish line clearly, that is probably the real problem. A lot of projects are broken down into work, but not into milestones.
“Work on migration” is not a finish line. “Cut 10% of traffic over to the new system” is.
“Work on search performance” is not a finish line. “Ship the first optimization and compare P95 latency before and after” is.
If you can’t say what “done for this week” looks like, start there.
Own the outcome, not just your part
Some will say: okay, but how can I commit to “get the PR merged” if I need someone else to review it?
You own the outcome. Not just your part of it. Once something is your A problem, you are responsible for getting it across the finish line, even when it depends on someone else.
A sent PR can be a finish line. A merged PR is a later finish line. Both can be valid. The important thing is to be explicit about which one matters this week.
The mistake is not picking a smaller milestone. The mistake is being vague about what “done for this week” actually means, and then assuming your responsibility ended once you did your part.
If the work is blocked on review, follow up. Ping the reviewer. Tell them why it matters. Post it in the review channel. Ask your manager for help if needed. Make it easy for the other person to unblock you.
In Alex’s case, once Sam hadn’t reviewed the PR by Tuesday, she should have nudged him. And once comments showed up on Thursday, she should have seriously considered switching back right then, because the shortest path to value was now to finish the nearly-done thing.
There is another angle here too: sometimes the issue is not just that you failed to chase the review. Sometimes the review process itself is telling you something.
Are the PRs too large? Are design questions surfacing in code review that should have been discussed earlier? Does the team actually have a shared expectation for review turnaround? If reviews routinely take several days, that is not just an individual execution issue. That may be a team process issue.
Owning the outcome includes improving those conditions over time too.
And while you are waiting, try to stay in the same context if you can. Alex didn’t have to jump immediately to a completely different project. She could have used that time to finalize the limits, think through rollout, check staging readiness, or write down edge cases.
Sometimes you really do have to switch to something unrelated. That happens. But if your A problem is briefly blocked, the default should still be to keep pushing that same thread forward wherever you can.
Avoid too many goals
If Alex starts the week with five goals and finishes two, she feels behind.
If she starts with two meaningful goals and finishes both, that is a good week, even if the total amount of work done is similar.
This sounds obvious, but it matters a lot in practice. When the list is too long, everything feels important and nothing gets protected. Then the plan starts to fall apart by Wednesday, and by Friday you are mostly reacting.
A long queue by itself is not the problem. The problem is when too many items on that queue feel like they should all be happening right now.
A shorter list changes behavior. You cancel one non-essential meeting. You protect an hour of focus time. You follow up faster. You do the boring last-mile work because the finish line actually feels achievable.
If you pick five A problems, you have not created a framework. You have just renamed your task list.
The last 20% is the hardest
The last 20% is where people bail.
Not necessarily because it is technically hard. A lot of the time it is just annoying. The interesting part is done. What is left is review, approvals, staging, rollout, follow-up, cleanup, and fixing whatever breaks. It is the unglamorous tail end of the work.
But that is exactly where a lot of the value shows up.
It is also where the unknowns appear. Alex gets to staging and realizes Redis is not provisioned there. Now she has an infrastructure problem she didn’t plan for. Maybe ideally that would have been caught earlier, but this is how real work goes. You only find these things by pushing the project forward.
And staying focused doesn’t mean stubbornly doing the same thing in the same order no matter what. You can also be smart about how you execute.
Sometimes the right move is to push a thin slice to staging earlier, test the riskiest assumption first, or do the smallest thing that surfaces hidden dependencies. In Alex’s case, an earlier pass through staging may have exposed the Redis problem sooner. Even a simpler first rollout plan might have helped her learn faster what the real blockers were.
The goal is not just to work hard. It is to learn early where the real complexity is, while still keeping the finish line in view.
This is also why I think AI can make the problem worse. Starting something new is now cheaper than ever. You can scaffold a feature in minutes and feel productive. But AI did not make finishing cheaper. It still won’t chase a reviewer, sort out staging, or handle the messy coordination near the end.
Make it stick
This works much better when someone else knows your A problems.
Tell your manager. Tell a peer. Tell a friend. Say it out loud.
Once you say, “My A problem this week is getting rate limiting merged,” it stops feeling like one item on a giant list and starts feeling like a commitment.
That small bit of accountability helps more than people think.
For next week
So here’s what I’d suggest:
- Start with the facts: commitments, dependencies, approvals, deadlines, and any new input that came in.
- Turn those into possible finish lines for the week.
- Pick one to three A problems: finish lines that matter now and are realistic for this week.
- Treat everything else as a B problem.
- If an A problem gets blocked, manage the dependency or keep pushing the same thread forward in some other way.
- On Friday, ask yourself: what actually crossed a finish line?
If you want extra accountability, subscribe to the newsletter below and reply to the first email with your A problem for next week. I’ll check in on Friday and ask how it went.
Enjoyed this post?
I send an email every two weeks about computer science and software engineering. No fluff, no hype — just the mechanism behind the things we use every day.