Initial Block Download
In the previous post, we implemented the handshake protocol.
In this post, we will implement the initial block download protocol and learn:
- What are headers and getheaders messages
- What is an initial block download process (IBD)
- What is a block index
- What is a block locator object
- History of initial block download (IBD) in Bitcoin
When a full node connects to the network, it first downloads the full blockchain before moving on to tasks such as validation or mining (unless the node is a lightweight node). If it is a brand-new node, it only knows about the genesis block. The new node will have to download hundreds of thousands of blocks to synchronize with the network and re-create the full blockchain.
The process starts with the version message, including the information about the best-known height from each peer. A node compares this information with its view of the blockchain and sends a getblocks message containing the information about the top block in the local blockchain. The peer receiving the getblocks message finds the part of the active blockchain that is missing and responds with the inv message containing up to 500 block hashes. Upon receiving the inv message, the node sends getdata messages requesting full block data for the blocks in the inv message.

The above diagram shows the structure of the inv message in Bitcoin protocol. The message starts with the number of hashes N, followed by N objects, each containing a type and a hash. Inv message is used for sending both transaction and block hashes, hence the need for object type.
The node should spread the load to all its peers to avoid overwhelming one peer with too many requests. However, I understand that the original implementation only requests blocks from a single peer, which makes the sync process very slow.
The main disadvantage of this approach is that the local node downloads blocks without having any clue if they are part of the active chain or not. This approach allows the malicious peer to send blocks that are not part of the active blockchain, and the node would spend time downloading them, which may lead to a slow sync process and disk fill attacks.
You may find mentions of other disadvantages, in particular, speed limitations, because all getdata requests are made to the sync node. If that node has a limited bandwidth, the initial block download process is prolonged.
I’m not convinced that the speed is a problem in the blocks-first approach because the node can download blocks in parallel from multiple peers.
This approach is known as blocks-first sync.
Orphan blocks
While we are discussing the old implementation, it’s worth mentioning orphan blocks. A node may receive blocks out of order from the network, which means that not every block has a parent in the blockchain at all times. For example, when two blocks are mined quickly, one after the other, the child may arrive before the parent.
Blocks without a parent block in the local node’s view are called orphan blocks. The node can’t know that the block is an orphan node without downloading its header, which includes the hash of the parent block. There is no API to request a block header only, so the node has to download the full block before it determines whether a block is an orphan or not.
LearnCoin doesn’t have a concept of orphan blocks because it uses a newer approach, which avoids book-keeping of orphan blocks.
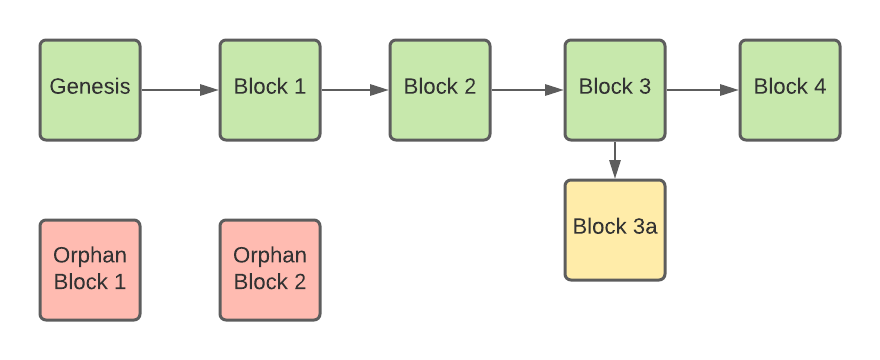
The above diagram shows orphan blocks that don’t have a parent in the blockchain.
Headers-first sync
Newer versions of Bitcoin use an approach where a node builds a partial view of the blockchain using block headers only, without downloading full block data. The node chooses one of the peers as a sync node and starts the initial block download process by sending the getheaders message. Like the old approach, the getheaders message includes the information about the blocks that the node knows about.
Upon receiving the getheaders message, the peer finds the part of the active chain that the node doesn’t know about and responds with the headers message. The response includes up to 2000 block headers. Upon receiving the response, the node again sends getheaders message. The process repeats until the node receives a headers message with unseen blocks, and the initial block download is completed.
The main difference between headers and inv messages is that the former includes full block header information, while the latter comes only with the block hash. The node uses block headers to construct the full blockchain tree and partially validate it before downloading any blocks.
After the node partially validates the received block headers, it starts two processes in parallel:
- Download more headers, if any, as described above. Once the node receives a headers message with no new block headers, it requests headers from other peers to get their view of the blockchain. It further uses this data to determine if the headers it downloaded from the sync peer are the best. Malicious sync node can be discovered quickly, as long as the node is connected to at least one honest peer. Note that the malicious peer cannot lie indefinitely about the blockchain because it has to provide valid proof of work, which is expensive.
- Download full block information, i.e. transactions, for each block via getdata messages using block hashes from the previously received block headers. The node requests full block from all of its peers in parallel, to avoid overwhelming one peer and limit the speed to the peer’s upload bandwidth. The node may request up to 16 blocks at a time from a single peer to spread the load among multiple peers.
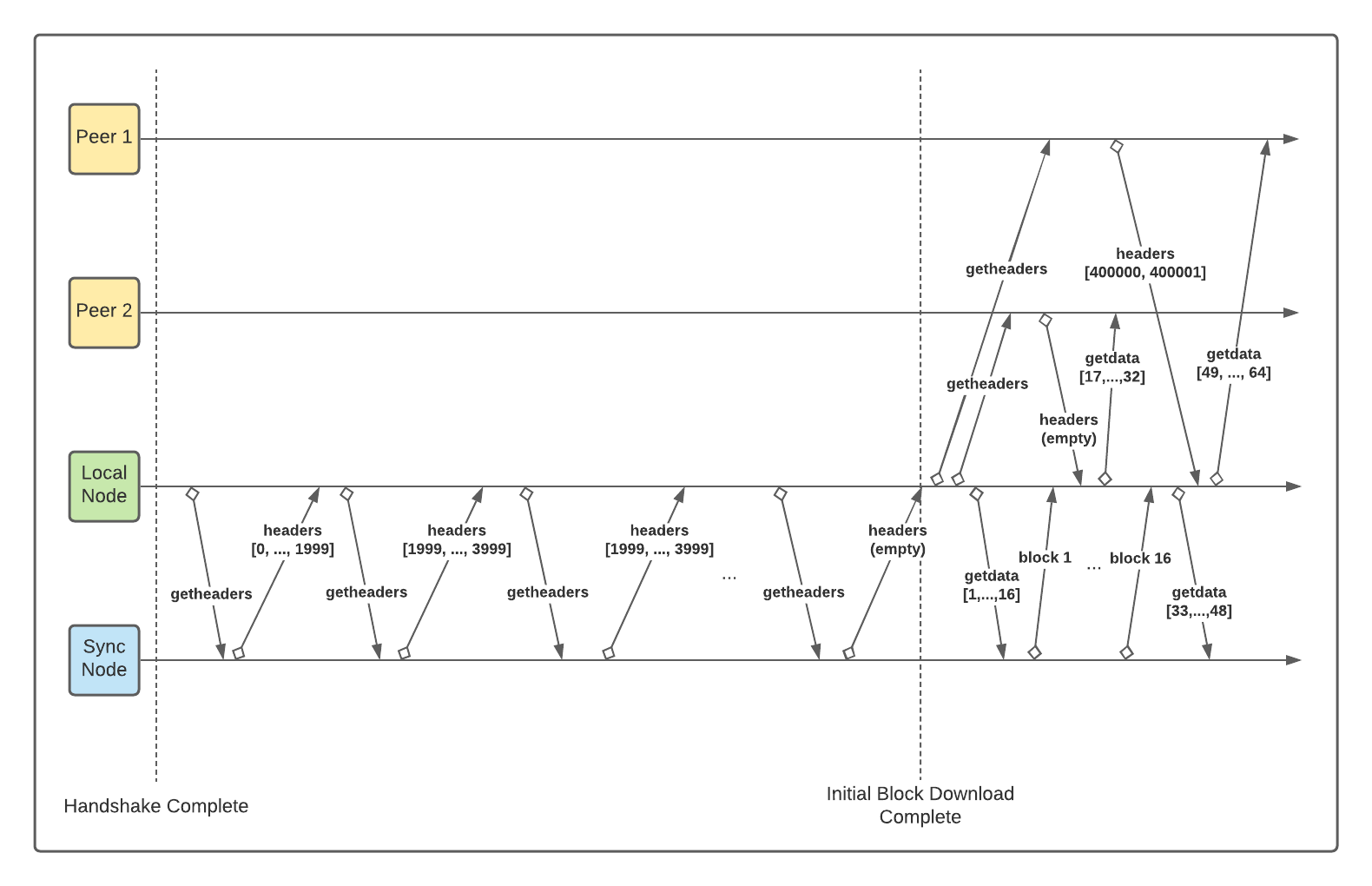
This approach is known as the headers-first sync, and we will implement it in LearnCoin.
Why not send getheaders to all peers immediately?
I’ve been wondering this too. The best explanation that I came up with is that a node can send getheaders messages to all peers immediately and simplify the sync process by not worrying about the sync node. However, the node initially chooses a single sync node to avoid receiving the same headers from all the peers, which is bandwidth optimization.
The size of ~400k (roughly the size of the active chain) is about 32MB. The node usually connects to about ~8 peers, so the overhead during the initial block download would be about 224MB. Given that the full node has to download full block data, ~360GB, as of October 2021, the 224MB is not worth the extra complexity.
However, lightweight nodes don’t have to download the full block data, and the saved bandwidth is worth it.
Block index
Before diving into the initial block download, let’s first implement a data structure to store all block headers the node receives from its peers and some metadata about the block, such as its height or total mining work. We will call it a block index.
// learncoin/src/block_index.rs
/// Represents a node of the tree, which is an implementation detail of the block tree, so it's not
/// part of the API.
pub struct BlockIndexNode {
pub block_header: BlockHeader,
// Distance to the genesis block.
pub height: usize,
// Total mining work required to mine the block header.
pub chain_work: u64,
}
/// The blockchain is a tree shaped structure starting with the Genesis block at the root,
/// with each block potentially having multiple children, but only one of them is part of
/// the active chain.
pub struct BlockIndex {
// Blocks that have a parent in the network, indexed by their hash.
tree: HashMap<BlockHash, BlockIndexNode>,
}Let’s also provide a constructor of the block index given the Genesis block. The height and required mining work for the Genesis block are zero.
// learncoin/src/block_index.rs
// ...
impl BlockIndex {
pub fn new(genesis_block: Block) -> Self {
let mut tree = HashMap::new();
let genesis_hash = genesis_block.header().hash();
tree.insert(
genesis_hash,
BlockIndexNode {
block_header: genesis_block.header().clone(),
height: 0,
chain_work: 0,
},
);
Self { tree }
}
}Finally, let’s add an API to insert a new block header in the block index. For the time being, we will approximate the chain work using the height of the block.
// learncoin/src/block_index.rs
// ...
impl BlockIndex {
// ...
/// Adds a new block to the blockchain and updates the active blockchain if needed.
///
/// Preconditions:
/// - The parent exists.
pub fn insert(&mut self, block_header: BlockHeader) {
let parent_hash = block_header.previous_block_hash();
let parent = self.tree.get(&parent_hash).unwrap();
let height = parent.height + 1;
// For the time being, we approximate the total chain work via block height.
let chain_work = parent.chain_work + 1;
let previous = self.tree.insert(
block_header.hash(),
BlockIndexNode {
block_header,
height,
chain_work,
},
);
assert!(previous.is_none());
}
}Let’s also introduce a concept to represent the active chain.
// learncoin/src/active_chain.rs
/// Represents an active chain in the blockchain.
pub struct ActiveChain {
/// A list of blocks starting with the Genesis block
hashes: Vec<Block>,
}
impl ActiveChain {
pub fn new(genesis_block: Block) -> Self {
Self {
hashes: vec![genesis_block],
}
}
pub fn tip(&self) -> &Block {
self.hashes.last().unwrap()
}
pub fn accept_block(&mut self, block: Block) {
self.hashes.push(block);
}
pub fn hashes(&self) -> &Vec<Block> {
&self.hashes
}
}Block locator object
We have mentioned a few times already that getblocks and getheaders messages include the information about the blocks that the node knows about. This information is called the block locator object.
Let’s consider two nodes, A and B. Node A would like to send getheaders message to node B, so it must construct a proper block locator object. A’s active chain may not be on the same branch as B’s active chain, so the locator object includes hashes starting from the tip and going back to the Genesis block, allowing node B to find the part that A is missing (see below diagram).
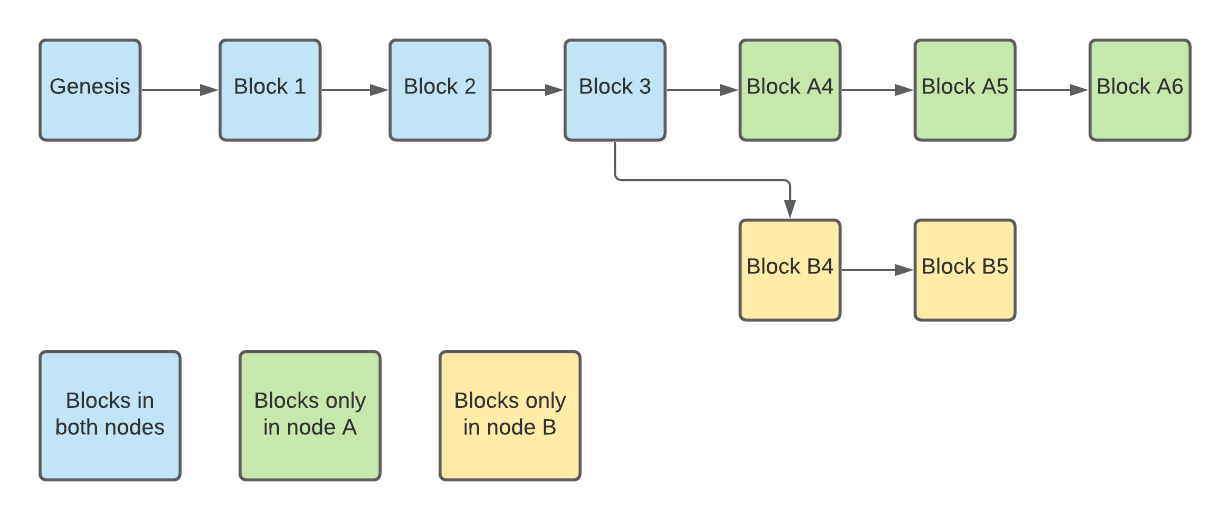
In the above diagram, node A sends information about its active chain, i.e. the chain starting with the Genesis block and ending with block A6. Node B detects that “Block 3” is the latest block node A knows about and responds with headers containing “Block B4” and “Block B5”. However, the locator object would be humongous if it included the whole active chain. Instead, it contains only a subset of the active chain, allowing node B to find the missing part efficiently. The most common scenario is that the last couple of blocks are missing, so the locator object includes more blocks that are closer to the tip using the following algorithm:
- Include the tip.
- Skip N blocks. N is 0 for the first 10 blocks, then it grows exponentially for each block.
- Include the next block hash.
- Repeat 1), 2) and 3) until there are no more blocks left.
- Ensure the Genesis block is included.
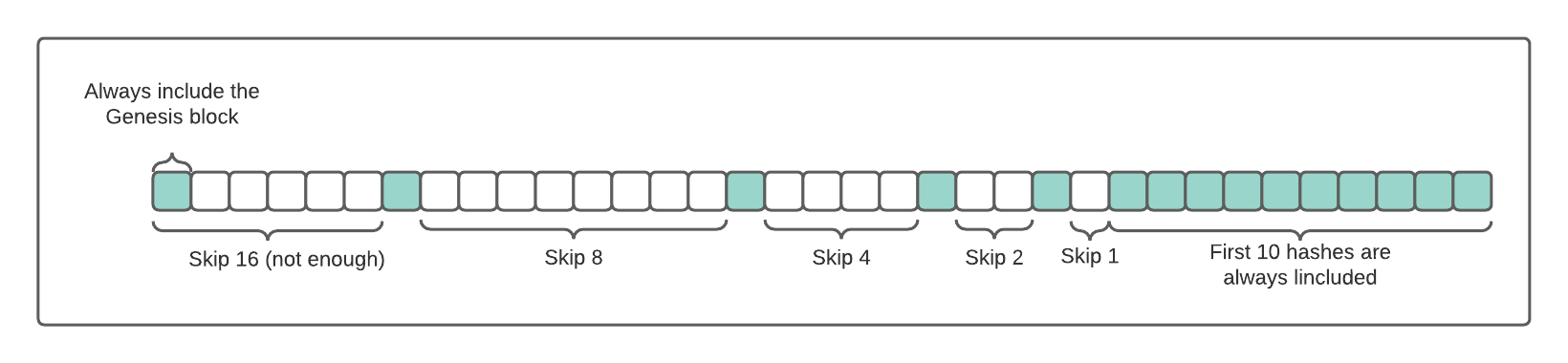
The above diagram highlights the block hashes that are included in the block locator object. The density of the included blocks drops exponentially.
Going back to our example, node B finds the latest block it knows about in the block locator object. Usually, that would be the latest block in the block locator object, indicating that the peer hasn’t synced the blockchain yet. In that case, node B responds to A with the subsequent 2000 block headers.
However, it is possible that the latest block from the locator object doesn’t exist in B’s active chain. In that case, B finds the latest one that does exist and sends the following 2000 block headers starting from the next one.
The main advantage of the block locator object is that it enables a node to describe the state of its active chain without sending a lot of information over the network. Furthermore, it assumes that the divergence between peers’ chains is likely to appear in more recent blocks – which is true in practice because the most common scenario is mining a new block.
The main disadvantage is that it loses granularity after ten blocks, which means that the sender may include some redundant information. However, this scenario is rare.
Let’s introduce a block locator object concept in our code. We will store it as a vector of block hashes, sorted by their height in descending order. Since this concept will be sent over the network, we derive Serialize and Deserialize traits. If you are following in a different language, make sure to encode and decode this object.
use crate::BlockHash;
use serde::{Deserialize, Serialize};
#[derive(Debug, Clone, Eq, PartialEq, Serialize, Deserialize)]
pub struct BlockLocatorObject {
hashes: Vec<BlockHash>,
}After defining the block locator object, let’s implement a function to build the block locator object starting from the given block hash.
// learncoin/src/block_index.rs
// ...
impl BlockIndex {
// ...
/// Returns the block locator object.
///
/// Preconditions:
/// - block_hash must exist
pub fn locator(&self, block_hash: &BlockHash) -> BlockLocatorObject {
let entry = self.tree.get(block_hash);
assert!(entry.is_some());
let entry = entry.unwrap();
let mut hashes = vec![];
let mut height = entry.height;
let mut step = 1;
loop {
// Ancestor must always exist because all blocks have parents,
// and the given block hash exists at this moment.
hashes.push(
self.ancestor(block_hash, height)
.unwrap()
.block_header
.hash(),
);
if height == 0 {
// Genesis block has been inserted.
break;
}
if hashes.len() >= 10 {
step *= 2;
}
if step >= height {
// Ensure we don't skip the genesis block.
height = 0;
} else {
height -= step;
}
}
BlockLocatorObject::new(hashes)
}
}The above code implements the described algorithm. It uses the ancestor function that returns the ancestor of a block hash at the given height.
// learncoin/src/block_tree.rs
// ...
impl BlockIndex {
// ...
/// Returns the ancestor of the given block hash at the given height or
/// None if the given block hash doesn't exist in the tree.
///
/// Preconditions:
/// - Height is less than or equal to the height of the given block hash.
pub fn ancestor(&self, block_hash: &BlockHash, height: usize) -> Option<&BlockIndexNode> {
match self.tree.get(&block_hash) {
None => None,
Some(current) => {
assert!(height <= current.height);
if current.height == height {
Some(current)
} else {
self.ancestor(¤t.block_header.previous_block_hash(), height)
}
}
}
}
}The algorithm of the ancestor function starts with the given block hash, then jumps to its parent, parent’s parent, etc., until it reaches the block at the given height. This implementation may be too slow when the blockchain grows to thousands of blocks – the complexity is O(N). However, we’ll keep this implementation due to its simplicity and ease of presentation.
A way to improve the complexity of the function is to store a reference to ancestors at heights H – 2^0, H – 2^1, …, H – 2^n, which can be used to skip a lot of blocks and find the ancestor block in O(log N). This data structure is called a skip list – we may come back to implement this in future blog posts.
Initial headers retrieval
That was a lot of preparation! However, it was necessary before implementing the IBD protocol.
Initialize block index
Let’s begin with introducing the block index, active chain, and the information to track the state of the initial headers sync. The node tracks the ID of the sync node and whether the initial header sync is complete.
// learncoin/src/learncoin_node.rs
pub struct LearnCoinNode {
// ... existing fields
block_index: BlockIndex,
active_chain: ActiveChain,
sync_node: Option<String>,
is_initial_header_sync_complete: bool,
}
impl LearnCoinNode {
pub fn connect(network_params: NetworkParams, version: u32) -> Result<Self, String> {
// ...
// Initial headers sync is automatically complete if this node is the only node in
// the network.
let is_initial_header_sync_complete = network_params.peers().is_empty();
let active_chain = ActiveChain::new(Self::genesis_block());
Ok(Self {
network,
version,
peer_states,
block_index: BlockIndex::new(Self::genesis_block()),
active_chain,
sync_node: None,
is_initial_header_sync_complete,
})
}
pub fn genesis_block() -> Block {
// 02 Sep 2021 at ~08:58
let timestamp = 1630569467;
const GENESIS_REWARD: i64 = 50;
let inputs = vec![TransactionInput::new_coinbase()];
let outputs = vec![TransactionOutput::new(GENESIS_REWARD)];
let transactions = vec![Transaction::new(inputs, outputs).unwrap()];
let previous_block_hash = BlockHash::new(Sha256::from_raw([0; 32]));
let merkle_root = MerkleTree::merkle_root_from_transactions(&transactions);
// An arbitrary initial difficulty.
let difficulty = 8;
let nonce =
ProofOfWork::compute_nonce(&previous_block_hash, &merkle_root, timestamp, difficulty)
.expect("can't find nonce for the genesis block");
Block::new(
previous_block_hash,
timestamp,
difficulty,
nonce,
transactions,
)
}
}We have also introduced a function to create the Genesis block. Some data such as reward and difficulty are hard-coded for the time being.
Extend the protocol
Let’s introduce new messages in the network protocol.
// learncoin/src/peer_message.rs
// ...
pub enum PeerMessagePayload {
// ... existing messages
GetHeaders(BlockLocatorObject),
Headers(Vec<BlockHeader>),
}Note that BlockHeader is now part of the network protocol, so we must provide encoding and decoding for it. Go ahead and derive Serialize and Deserialize traits for it and all of its dependencies – this is almost all of the core concepts we’ve introduced so far.
If you are following in a different language, make sure to provide encoding and decoding for the necessary types.
Initiate the IBD with the sync node
The next step is to add functionality that starts the IBD process. We do that by iterating over each peer and sending the getheaders message if the IBD flag is not set and the handshake with the peer is complete.
// learncoin/src/learncoin_node.rs
// ...
impl LearnCoinNode {
// ...
pub fn run(mut self) -> Result<(), String> {
// ...
loop {
// ...
for peer_address in self.peer_addresses() {
self.maybe_send_messages(&peer_address);
}
// ... self.network.drop_inactive_peers() comes next
}
}
fn maybe_send_messages(&mut self, peer_address: &str) {
let peer_state = self.peer_states.get_mut(peer_address).unwrap();
// Send initial HEADERS message.
if self.is_initial_header_sync_complete {
return;
}
let is_handshake_complete =
!peer_state.expect_verack_message && !peer_state.expect_version_message;
if !is_handshake_complete {
return;
}
if self.sync_node.is_none() {
self.sync_node = Some(peer_address.to_string());
let locator = self.block_index.locator(self.active_chain.tip().id());
self.network
.send(peer_address, &PeerMessagePayload::GetHeaders(locator));
}
}
}We create the locator object from the tip of the active chain, which is always the Genesis block at the moment. However, the node may load blocks from a disk before starting the IBD in the future, which is useful when a node crashes because it avoids syncing the entire blockchain from scratch again.
Process get headers message
Let’s handle the getheaders message next as described in the headers-first sync section. To summarize, the receiving node finds the latest block hash in the locator object that is part of the node’s active chain. The latest block is the first one in the locator object because hashes are sorted by their height in descending order. The node responds with the headers message containing up to 2000 hashes from the active chain after the matched hash.
// learncoin/src/learncoin_node.rs
const MAX_HEADERS_SIZE: u32 = 2000;
// ...
impl LearnCoinNode {
// ...
fn on_get_headers(&mut self, peer_address: &str, block_locator_object: BlockLocatorObject) {
let active_blockchain = self
.active_chain
.hashes()
.iter()
.map(|block| block.header().clone())
.collect::<Vec<BlockHeader>>();
// Find the first block hash in the locator object that is in the active blockchain.
// If no such block hash exists, the peer is misbehaving because at least the genesis block
// should exist.
for locator_hash in block_locator_object.hashes() {
match active_blockchain
.iter()
.position(|header| header.hash() == *locator_hash)
{
None => {
// No such block exists in the active blockchain.
}
Some(locator_hash_index) => {
// Found a block that exists in the active blockchain.
// Respond with the headers containing up to MAX_HEADERS_SIZE block hashes.
let headers = active_blockchain
.into_iter()
.skip(locator_hash_index + 1)
.take(MAX_HEADERS_SIZE as usize)
.collect();
self.network
.send(peer_address, &PeerMessagePayload::Headers(headers));
return;
}
}
}
// No blocks from the locator object have been found. The peer is misbehaving.
self.close_peer_connection(
peer_address,
&format!("Locator object must include the genesis block"),
);
}
}Process headers message
The next step is to handle the headers message. Each block hash in the headers message is expected to have a parent in the block index. If the block header doesn’t already exist, insert it into the block index.
The function keeps track of whether there are new blocks in the headers message, and if so, it requests the new headers from the same peer. The node creates a locator object starting with the last block hash received from the peer. It doesn’t build it from the active chain’s tip because the tip doesn’t change unless the block has been fully validated, requiring transaction data.
// learncoin/src/learncoin_node.rs
// ...
impl LearnCoinNode {
// ...
fn on_headers(&mut self, peer_address: &str, headers: Vec<BlockHeader>) {
let mut last_new_block_hash = None;
for header in headers {
if !self.block_index.exists(&header.previous_block_hash()) {
// Peer is misbehaving, the headers don't connect.
self.close_peer_connection(
peer_address,
"Peer is misbehaving. The block headers do not connect.",
);
return;
} else if !self.block_index.exists(&header.hash()) {
last_new_block_hash = Some(header.hash());
self.block_index.insert(header);
}
}
match last_new_block_hash {
None => {
// Do not request any more headers from the peer,
// because it doesn't have anything new.
if let Some(sync_node) = &self.sync_node {
if sync_node == peer_address {
// If the empty headers comes from the sync node, then the node has caught
// up with the sync node's view of the active chain.
// Therefore, the initial header sync is complete.
self.is_initial_header_sync_complete = true;
self.sync_node = None;
}
}
}
Some(last_new_block_hash) => {
// Sync node has sent us new information. Request more headers.
let locator = self.block_index.locator(&last_new_block_hash);
self.network
.send(peer_address, &PeerMessagePayload::GetHeaders(locator));
}
}
}
}Finally, let’s ensure the new messages are processed.
// learncoin/src/learncoin_node.rs
// ...
impl LearnCoinNode {
// ...
fn on_message(&mut self, peer_address: &str, message: PeerMessagePayload) {
match message {
// ... existing messages
PeerMessagePayload::GetHeaders(block_locator_object) => {
self.on_get_headers(peer_address, block_locator_object)
}
PeerMessagePayload::Headers(headers) => self.on_headers(peer_address, headers),
}
}
}You may notice that we don’t do any validation nor download block data yet. We will implement both in future posts.
Here’s the source code of the work we’ve done so far in this post.
Protecting against misbehaving peers
What we’ve done so far is amazing! However, there are a couple of issues that we haven’t addressed:
- What happens if the sync node never responds with headers message?
- What if the sync node is malicious and their blockchain is is not the best?
Check timeouts
The node stores the time when it sends a getheaders message to the sync node. If the sync node doesn’t respond with the headers message after some time, we say it’s misbehaving, and the node closes the connection. The node chooses another peer to be the sync node.
Let’s introduce a new field to track the time when a node sends the headers message.
// learncoin/src/peer_state.rs
pub struct PeerState {
// ...
pub headers_message_sent_at: Option<Instant>,
}We extend the maybe_send_messages and on_headers functions to take the current time and store it whenever the node sends a getheaders message.
Note that there is at most one in-flight getheaders message.
The node should never be in a state where it requests new headers while there is an unanswered request.
Also, the node resets the headers_message_sent_at when it receives the headers message.
// learncoin/src/learncoin_node.rs
// ...
impl LearnCoinNode {
// ...
pub fn run(mut self) -> Result<(), String> {
// ...
loop {
// ...
let current_time = Instant::now();
// ...
for (peer_address, messages) in all_messages {
for message in messages {
self.on_message(&peer_address, message, current_time);
}
}
for peer_address in self.peer_addresses() {
self.maybe_send_messages(&peer_address, current_time);
}
// ...
}
}
// ...
fn maybe_send_messages(&mut self, peer_address: &str, current_time: Instant) {
// ...
if self.sync_node.is_none() {
// ... send getheaders goes here
peer_state.headers_message_sent_at = Some(current_time);
}
}
fn on_message(
&mut self,
peer_address: &str,
message: PeerMessagePayload,
current_time: Instant,
) {
match message {
// ...
PeerMessagePayload::Headers(headers) => {
self.on_headers(peer_address, headers, current_time)
}
}
}
fn on_headers(&mut self, peer_address: &str, headers: Vec<BlockHeader>, current_time: Instant) {
let mut peer_state = self.peer_states.get_mut(peer_address).unwrap();
peer_state.headers_message_sent_at = None;
// ...
match last_new_block_hash {
// ...
Some(last_new_block_hash) => {
// ...
peer_state.headers_message_sent_at = Some(current_time);
}
}
}
}Finally, let’s check if a peer is late with the response, and if so, disconnect it.
// learncoin/src/learncoin_node.rs
// ...
const HEADERS_RESPONSE_TIMEOUT: Duration = Duration::from_millis(60_000);
// ...
impl LearnCoinNode {
// ...
pub fn run(mut self) -> Result<(), String> {
// ...
loop {
// ...
for peer_address in self.peer_addresses() {
self.maybe_send_messages(&peer_address, current_time);
self.check_timeouts(&peer_address, current_time);
}
// ...
}
}
// ...
fn check_timeouts(&mut self, peer_address: &str, current_time: Instant) {
let peer_state = self.peer_states.get_mut(peer_address).unwrap();
match peer_state.headers_message_sent_at {
None => {
// Nothing to do since there are no in-flight headers messages.
}
Some(headers_message_sent_at) => {
let elapsed = current_time.duration_since(headers_message_sent_at);
if elapsed.gt(&HEADERS_RESPONSE_TIMEOUT) {
self.close_peer_connection(
peer_address,
&format!(
"Response to getheaders has timed out after {} ms",
HEADERS_RESPONSE_TIMEOUT.as_millis()
),
);
// If it's the sync node that didn't respond, it is not a sync node anymore.
if let Some(sync_node) = &self.sync_node {
if sync_node == peer_address {
self.sync_node = None;
}
}
}
}
}
}
}Here’s the source code for the change that checks if a getheaders request has timed out.
Get headers from all peers
If the sync node doesn’t have the best chain, the local node won’t have it either. Therefore the node must request headers from all its peers eventually.
Let’s update the node logic to send getheaders messages to all the peers after receiving the last headers message from the sync node.
// learncoin/src/learncoin_node.rs
// ...
impl LearnCoinNode {
// ...
fn on_headers(&mut self, peer_address: &str, headers: Vec<BlockHeader>, current_time: Instant) {
// ...
match last_new_block_hash {
None => {
if let Some(sync_node) = &self.sync_node {
if sync_node == peer_address {
let sync_node_state = self.peer_states.get(sync_node).unwrap();
// ...
// Send headers message to each peer.
// It's okay to send a redundant headers message to the sync node,
// which will respond with another empty headeres message.
for peer_address in self.peer_addresses() {
// Use last known hash from the sync node as that's the latest
// block hash the node knows about.
let locator = self.block_index.locator(&sync_node_state.last_known_hash);
self.network
.send(&peer_address, &PeerMessagePayload::GetHeaders(locator));
}
}
}
}
Some(last_new_block_hash) => {
// ...
peer_state.last_known_hash = last_new_block_hash;
}
}
}The node builds the locator object from the last block hash it received from the sync node, enabling peers to avoid sending redundant information. The node stores the last known hash for each peer in the peer state.
// learncoin/src/peer_state.rs
pub struct PeerState {
// ...
pub last_known_hash: BlockHash,
}
impl PeerState {
pub fn new(genesis_hash: BlockHash) -> Self {
Self {
// ...
last_known_hash: genesis_hash,
}
}
}We assume that every peer knows about the genesis block, which requires us to pass the genesis block whenever a new peer connects.
Here’s the source code diff for the change that sends headers to all peers.
Download full block data
Before we conclude this post, let’s finish the last part of the IBD, i.e. download full block data.
As mentioned previously, when the initial list of headers is downloaded from the sync node, the local node sends a series of getdata messages to all peers as shown in the headers-first sync diagram.
Which blocks to download from which peer?
Each peer has an active chain that it believes is the best, and it may not be aware of any other chains at the moment. Therefore, it makes sense to download only the blocks from the peer’s active chain. In practice, most peers would have the same view of the active chain.
The node already tracks the last-known block hash for each peer in the PeerState, which is the tip of the peer’s active chain.
The block download process uses a sliding window to mazimize the download speed.
The lowest-height block in the window is the next block to be validated, and the node may download only the blocks within the window.
We will implement validation in future blog posts, so our validation criteria at the moment is that the full block data is available.
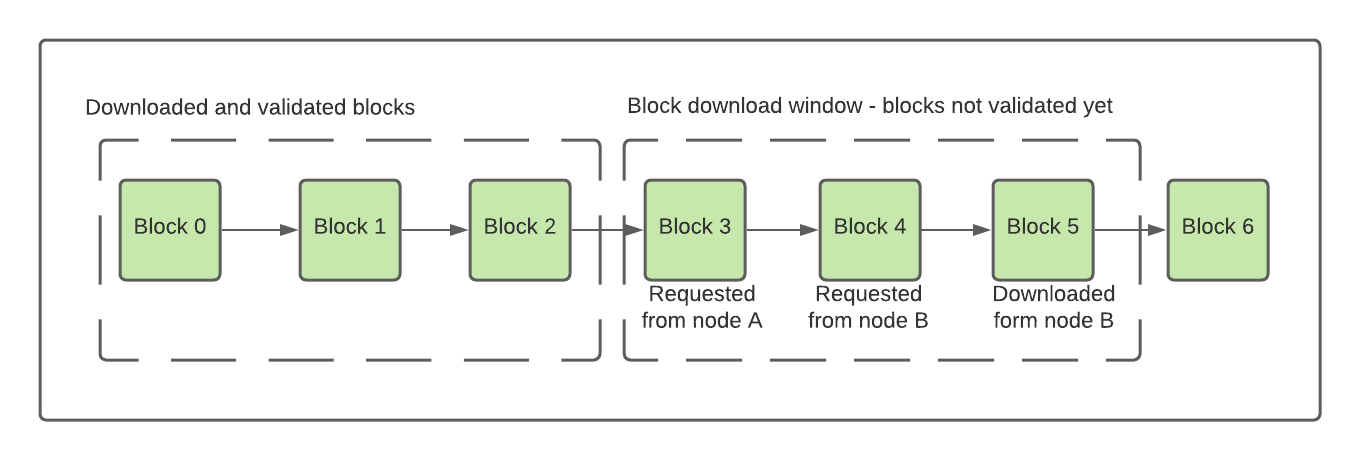
In the above diagram, blocks 0, 1, and 2 have been fully downloaded and validated. The sliding window starts with block 3. The size of the sliding window is 1024 blocks, but let’s assume it includes only 3 blocks for the purpose of the example, i.e. it includes only blocks 3, 4 and 5. The node requests to download up to 16 blocks from the window.
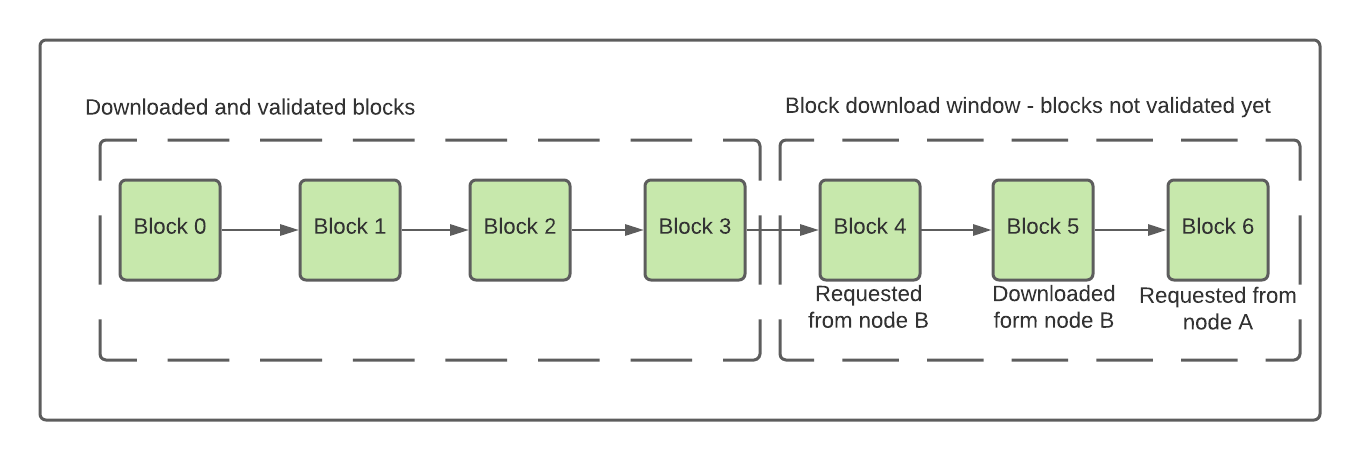
In the above diagram, blocks 3 has been downloaded and validated, so the window advances to the next block that is not validated.
The node keeps track of how many blocks it requested to download from each peer, and the last common block that’s been fully downloaded and validated.
// learncoin/src/peer_state.rs
pub struct PeerState {
// ... existing fields
pub last_common_block: BlockHash,
pub num_blocks_in_transit: usize,
}We also need a place to store the blocks, e.g. a persistent storage or in-memory. Let’s introduce a concept called block storage that stores full block data. The initial implementation will store the blocks in RAM.
pub struct BlockStorage {
blocks: HashMap<BlockHash, Block>,
}
impl BlockStorage {
pub fn new(genesis_block: Block) -> Self {
let mut blocks = HashMap::new();
blocks.insert(*genesis_block.id(), genesis_block);
Self { blocks }
}
pub fn exists(&self, block_hash: &BlockHash) -> bool {
self.blocks.contains_key(block_hash)
}
pub fn insert(&mut self, block: Block) {
self.blocks.insert(*block.id(), block);
}
pub fn get(&self, block_hash: &BlockHash) -> Option<&Block> {
self.blocks.get(block_hash)
}
}And let’s add it to the LearnCoinNode.
// learncoin/src/learncoin_node.rs
pub struct LearnCoinNode {
// ... existing fields
block_storage: BlockStorage,
}Ensure the same block is downloaded at most once
To use the bandwidth efficiently, the node should download blocks from multiple peers at the same time, and it should avoid downloading the same block twice. The node downloads up to 16 blocks from a single peer at the same time. On average, the node would connect to 8 peers, which results in 128 blocks being downloaded in parallel. With an average block size being 1MB, the node can download up to 128MB worth of block data in parallel.
To ensure the local node doesn’t download the same block twice, it keeps track of all in-flight requests. Let’s track this state in the local node.
// learncoin/src/learncoin_node.rs
// ...
struct InFlightBlockRequest {
peer_address: String,
sent_at: Instant,
}
pub struct LearnCoinNode {
// ... existing fields
in_flight_block_requests: HashMap<BlockHash, InFlightBlockRequest>,
}Find next blocks
The next step is to implement a function that finds which blocks to download from the given peer.
// learncoin/src/learncoin_node.rs
/// ...
const BLOCK_DOWNLOAD_WINDOW: usize = 1024;
impl LearnCoinNode {
// ...
fn find_next_blocks_to_download(
peer_state: &mut PeerState,
block_index: &mut BlockIndex,
block_storage: &mut BlockStorage,
in_flight_block_requests: &mut HashMap<BlockHash, InFlightBlockRequest>,
num_blocks_to_download: usize,
) -> Vec<BlockHash> {
// ... to be implemented
}
}The function takes necessary context, i.e. peer_state, block_index, block_storage and in_flight_block_requests, and number of blocks to download, i.e. num_blocks_to_download.
The node calls this function with num_blocks_to_download such that the total number of in-flight requests per peer doesn’t exceed 16.
Let’s implement it step by step.
Find the height of the last block in the sliding window, starting with the height of the last common block.
let last_common_block_index_node = block_index
.get_block_index_node(&peer_state.last_common_block)
.unwrap();
let last_known_block_index_node = block_index
.get_block_index_node(&peer_state.last_known_hash)
.unwrap();
let window_end = last_common_block_index_node.height + BLOCK_DOWNLOAD_WINDOW - 1;Since the sliding window may be larger than the number of remaining blocks, let’s ensure that the maximum height doesn’t exceed the last known block.
let max_height = min(window_end, last_known_block_index_node.height);At this stage, the node has a window from which it may download blocks. The node prefers to download blocks at lower heights to allow the sliding window to move sooner. It begins with the first block after the last common block, selects the ones that haven’t been downloaded yet.
let mut blocks_to_download = vec![];
let mut candidate_blocks = vec![last_known_block_index_node.block_header.hash()];
for i in 0..(num_blocks_to_fetch - 1) {
let last = candidate_blocks.last().unwrap();
let parent = block_index.parent(last).unwrap();
candidate_blocks.push(parent);
}
// Candidate blocks are inserted in reverse, i.e. children before parents.
// Order them such that blocks at lower heights come first.
candidate_blocks.reverse();The candidate blocks are all the blocks in the sliding window, so let’s filter only the ones that satisfy the download criteria.
for candidate in &candidate_blocks {
let is_already_downloaded = block_storage.exists(candidate);
let is_in_flight = in_flight_block_requests.contains_key(&candidate);
if !is_already_downloaded && !is_in_flight {
blocks_to_download.push(*candidate);
}
}Finally, let’s ensure that the sliding window is updated. It’s sufficient to set the last common block to the last candidate such that all blocks are fully downloaded. Note that the window should only update if the block is valid. However, we implement validation in future posts, so for now let’s ignore the validation requirement.
for candidate in &candidate_blocks {
let is_already_downloaded = block_storage.exists(candidate);
if !is_already_downloaded {
break;
}
// For the time being, we assume that the blocks are valid, so we update the last common block
// if the block is fully downloaded.
// However, this will change.
peer_state.last_common_block = *candidate;
}Finally, return the blocks_to_download.
Fetching blocks from the index can be expensive
You may notice that we retrieve the full window of blocks from the BlockIndex to construct the candidates list.
There’s a good chance that we don’t need to fetch full 1024 blocks to request only 16 blocks.
I don’t know how relevant this optimization is in practice since I haven’t measured it myself. However, the Bitcoin implementation fetches up to 128 blocks over multiple iterations instead of 1024 in one go, hoping that it won’t have to fetch all the blocks.
We don’t worry too much about optimizations in this project, but I’ve decided to implement this one anyway since it’s easy to do so. I’ll leave this one to you as an exercise, but if you don’t want to do it yourself you can look at the source code.
Extend the protocol
Now that we know which blocks to download, let’s extend the protocol to retrieve full block data.
// ...
pub enum PeerMessagePayload {
// ... existing fields
GetBlockData(Vec<BlockHash>),
Block(Block),
}Note that the getdata message in the Bitcoin protocol requests any type of data, i.e. transactions or blocks.
However, it’s much cleaner to split this into two messages, so we introduce GetBlockData message to retrieve blocks, and in future posts we will introduce GetTransactionData
Don’t forget to delegate the requests in the on_message function.
fn on_message(
&mut self,
peer_address: &str,
message: PeerMessagePayload,
current_time: Instant,
) {
match message {
// ...
PeerMessagePayload::GetBlockData(block_hashes) => {
self.on_get_block_data(peer_address, block_hashes)
}
PeerMessagePayload::Block(block) => self.on_block(peer_address, block),
}
}Process Block message
Let’s handle the block message first.
When a node receives the block message, it stores it in the block storage.
The block download request is not in-flight anymore, and we reduce the number of blocks in transit.
fn on_block(&mut self, peer_address: &str, block: Block) {
let peer_state = self.peer_states.get_mut(peer_address).unwrap();
peer_state.num_blocks_in_transit -= 1;
self.in_flight_block_requests.remove(block.id());
self.block_storage.insert(block);
}Process Get Block Data message
When a node receives getblockdata message, it searches for the block in the block_storage and sends it back to the peer.
The peer must request a valid block, otherwise it’s misbehaving.
fn on_get_block_data(&mut self, peer_address: &str, block_hashes: Vec<BlockHash>) {
for block_hash in block_hashes {
match self.block_storage.get(&block_hash) {
None => {
// Peer has requested invalid block.
self.close_peer_connection(
peer_address,
&format!(
"Peer is misbehaving. Requested invalid block: {}",
block_hash
),
);
return;
}
Some(block) => {
self.network
.send(peer_address, &PeerMessagePayload::Block(block.clone()));
}
}
}
}Send Get Block Data message
Refactor maybe_send_messages
The node periodically tries to send get data message to all its peers, in case they have new available blocks.
A natural place to add this functionality is maybe_send_messages function.
Let’s do some refactoring first, i.e. extract the logic from the maybe_send_messages into maybe_send_initial_headers, and call the underlying functions instead.
fn maybe_send_messages(&mut self, peer_address: &str, current_time: Instant) {
self.maybe_send_initial_headers(peer_address, current_time);
self.maybe_send_get_block_data(peer_address, current_time);
}Implement new functionality
Let’s implement the maybe_send_get_block_data function that sends getblockdata messages if needed.
Firstly, the function should not do anything if the initial synchronisation of headers is not complete.
fn maybe_send_get_data(&mut self, peer_address: &str, current_time: Instant) {
let Self {
is_initial_header_sync_complete,
peer_states,
block_index,
block_storage,
in_flight_block_requests,
..
} = self;
if !*is_initial_header_sync_complete {
return;
}
}If the initial headers sync is complete, the node finds which blocks to download from the given peer using find_next_blocks_to_download function that we’ve already implemented.
The node wants to download as many blocks as possible, such that the number of in-flight requests doesn’t exceed 16.
// learncoin/src/learncoin_node.rs
const MAX_BLOCKS_IN_TRANSIT_PER_PEER: usize = 16;
impl LearnCoinNode {
// ...
fn maybe_send_get_data(&mut self, peer_address: &str, current_time: Instant) {
// ...
let peer_state = peer_states.get_mut(peer_address).unwrap();
assert!(MAX_BLOCKS_IN_TRANSIT_PER_PEER >= peer_state.num_blocks_in_transit);
let num_free_slots = MAX_BLOCKS_IN_TRANSIT_PER_PEER - peer_state.num_blocks_in_transit;
let blocks_to_download = Self::find_next_blocks_to_download(
peer_state,
block_index,
block_storage,
in_flight_block_requests,
num_free_slots,
);
}
}If there are new blocks to download, update the peer state to reflect this and mark which block hashes are being downloaded. Finally, send the request to the peer.
fn maybe_send_get_data(&mut self, peer_address: &str, current_time: Instant) {
if !blocks_to_download.is_empty() {
peer_state.num_blocks_in_transit += blocks_to_download.len();
for block_to_download in &blocks_to_download {
let previous = in_flight_block_requests.insert(
*block_to_download,
InFlightBlockRequest {
peer_address: peer_address.to_string(),
sent_at: current_time,
},
);
assert!(previous.is_none());
}
self.network.send(
peer_address,
&PeerMessagePayload::GetBlockData(blocks_to_download),
);
}
}
Check timeouts
The peer may never respond with the requested block data, so let’s ensure the node is resilient to timeouts.
Before we do that, let’s repeat the refactor process that we’ve done for maybe_send_messages.
Extract the existing code from check_timeouts function into check_timeouts_get_headers, and add new function to check timeouts for get block data, i.e. check_timeouts_get_block_data.
Let’s check if any download requests have expired by iterating over all in-flight requests and removing them from the in_flight_block_requests.
If the peer fails to respond within the predefined timeframe, the node disconnects from it, assuming something is wrong with its connection.
fn check_timeouts_get_block_data(&mut self, peer_address: &str, current_time: Instant) {
let mut expired_block_requests = vec![];
for (block_hash, in_flight_block_request) in &self.in_flight_block_requests {
let elapsed = current_time.duration_since(in_flight_block_request.sent_at);
if elapsed.gt(&GET_BLOCK_DATA_RESPONSE_TIMEOUT) {
expired_block_requests.push(*block_hash);
}
}
for block_hash in expired_block_requests {
let expired_request = self.in_flight_block_requests.remove(&block_hash).unwrap();
self.close_peer_connection(
&expired_request.peer_address,
&format!(
"Response to get block data has timed out after {} ms for block {}.",
GET_BLOCK_DATA_RESPONSE_TIMEOUT.as_millis(),
block_hash
),
);
}
}Here’s the source code for downloading full block data.
Run the blockchain
Let’s start with two nodes that connect. We expect them to exchange getheaders and headers messages after the handshake is complete. Each response would be empty because both nodes have the same view of the blockchain, i.e., only the genesis block.
After the initial headers sync is complete, the nodes will exchange the headers again because the node sends getheaders too all the peers after the headers are downloaded from the sync node.
Output of the first node:
./learncoin server --address 127.0.0.1:8333
New peers connected: [
"127.0.0.1:62554",
]
[127.0.0.1:62554] Recv: Version(
VersionMessage {
version: 1,
},
)
[127.0.0.1:62554] Send: Verack
[127.0.0.1:62554] Send: GetHeaders(
BlockLocatorObject {
hashes: [
BlockHash(
00440e2238ebe96bf7013d7b86b4ec8293bb1bc0294444607817e73d8eecf1d1,
),
],
},
)
[127.0.0.1:62554] Recv: Headers(
[],
)
[127.0.0.1:62554] Recv: GetHeaders(
BlockLocatorObject {
hashes: [
BlockHash(
00440e2238ebe96bf7013d7b86b4ec8293bb1bc0294444607817e73d8eecf1d1,
),
],
},
)
Initial headers sync complete.
[127.0.0.1:62554] Send: GetHeaders(
BlockLocatorObject {
hashes: [
BlockHash(
00440e2238ebe96bf7013d7b86b4ec8293bb1bc0294444607817e73d8eecf1d1,
),
],
},
)
[127.0.0.1:62554] Send: Headers(
[],
)
[127.0.0.1:62554] Recv: Headers(
[],
)
[127.0.0.1:62554] Recv: GetHeaders(
BlockLocatorObject {
hashes: [
BlockHash(
00440e2238ebe96bf7013d7b86b4ec8293bb1bc0294444607817e73d8eecf1d1,
),
],
},
)
[127.0.0.1:62554] Send: Headers(
[],
)
Output of the second node:
./learncoin server --address 127.0.0.1:8334 --peers '127.0.0.1:8333'
[127.0.0.1:8333] Send: Version(
VersionMessage {
version: 1,
},
)
[127.0.0.1:8333] Recv: Verack
[127.0.0.1:8333] Recv: GetHeaders(
BlockLocatorObject {
hashes: [
BlockHash(
00440e2238ebe96bf7013d7b86b4ec8293bb1bc0294444607817e73d8eecf1d1,
),
],
},
)
[127.0.0.1:8333] Send: Headers(
[],
)
[127.0.0.1:8333] Send: GetHeaders(
BlockLocatorObject {
hashes: [
BlockHash(
00440e2238ebe96bf7013d7b86b4ec8293bb1bc0294444607817e73d8eecf1d1,
),
],
},
)
[127.0.0.1:8333] Recv: GetHeaders(
BlockLocatorObject {
hashes: [
BlockHash(
00440e2238ebe96bf7013d7b86b4ec8293bb1bc0294444607817e73d8eecf1d1,
),
],
},
)
[127.0.0.1:8333] Recv: Headers(
[],
)
[127.0.0.1:8333] Send: Headers(
[],
)
Initial headers sync complete.
[127.0.0.1:8333] Send: GetHeaders(
BlockLocatorObject {
hashes: [
BlockHash(
00440e2238ebe96bf7013d7b86b4ec8293bb1bc0294444607817e73d8eecf1d1,
),
],
},
)
[127.0.0.1:8333] Recv: Headers(
[],
)Notice that the nodes don’t send any getblockdata messages because they are both fully in sync.
Unfortunately, we won’t be able to see this in action until the network starts mining blocks.
Let’s also run the third node, expecting to exchange block headers with only one of the nodes.
./learncoin server --address 127.0.0.1:8335 --peers "127.0.0.1:8333,127.0.0.1:8334"
[127.0.0.1:8333] Send: Version(
VersionMessage {
version: 1,
},
)
[127.0.0.1:8334] Send: Version(
VersionMessage {
version: 1,
},
)
[127.0.0.1:8333] Recv: Verack
[127.0.0.1:8334] Recv: Verack
[127.0.0.1:8333] Send: GetHeaders(
BlockLocatorObject {
hashes: [
BlockHash(
00440e2238ebe96bf7013d7b86b4ec8293bb1bc0294444607817e73d8eecf1d1,
),
],
},
)
[127.0.0.1:8333] Recv: Headers(
[],
)
Initial headers sync complete.
[127.0.0.1:8333] Send: GetHeaders(
BlockLocatorObject {
hashes: [
BlockHash(
00440e2238ebe96bf7013d7b86b4ec8293bb1bc0294444607817e73d8eecf1d1,
),
],
},
)
[127.0.0.1:8334] Send: GetHeaders(
BlockLocatorObject {
hashes: [
BlockHash(
00440e2238ebe96bf7013d7b86b4ec8293bb1bc0294444607817e73d8eecf1d1,
),
],
},
)
[127.0.0.1:8333] Recv: Headers(
[],
)
[127.0.0.1:8334] Recv: Headers(
[],
)Summary
- Discussed two approaches to synchronize block data between nodes.
- Learned about the differences between the block-first and the headers-first approaches.
- Learned about getheaders and headers messages.
- Explained what an orphan block is.
- Explained what a block locator object is and implemented the algorithm to create one.
- Implemented a block index data structure to store the information about the block headers.
- Explained how a sliding window is used to download full block data.
- Implemented a protocol to download full block data from all peers in parallel.
- Implemented a flow-control to ensure peers don’t receive too many download requests at the same time.
- Ensured that the node is resilient to timeouts.
Here’s the source code for the whole blog post.
What’s next
Unfortunately, our network doesn’t mine any new blocks yet. We can’t see the effect of downloading new blocks yet.
In the next post, we will introduce a mining process and relay new blocks, which will require new nodes to download full block data.
Enjoyed this post?
I send an email every two weeks about computer science and software engineering. No fluff, no hype — just the mechanism behind the things we use every day.