Proof of Work and Mining
In the previous post, we explained block, block header, blockchain, and Merkle tree.
In this post, we are going to learn about:
- Proof of Work (PoW) algorithm and implement it
- Difficulty target and use it in the PoW algorithm
- A coinbase transaction
- Miner
- Consensus algorithm in the blockchain
As with every post, I would like to encourage you to implement everything in your way before looking at the code.
What is Proof of Work?
Proof-of-Work is a piece of data that requires significant computation to find but only a small amount of computation to verify as proven. In bitcoin, miners must find a numeric solution to the SHA-256 hash that meets the difficulty criteria.
The difficulty is a network-wide setting that controls how much computation is required to produce a proof of work.
Do you remember the difficulty and nonce fields from the block header? Nonce represents the solution that the miner is looking for, while difficulty and timestamp represent the criteria that the nonce must satisfy to mine a block.
Different nonce values result in different block hashes, even though the rest of the fields are the same. As a result, miners try different nonce values until the resulting block hash is less than or equal to the target hash.
The network calculates the target hash based on the current difficulty. The difficulty is a measure of how difficult it is to find a hash below a given target. In our case, the difficulty represents the number of leading zero bits in the 256-bit target hash. You can read more about the difficulty representation in the bitcoin protocol.
What is a coinbase transaction?
When a miner finds a block, it creates a new bitcoin and sends it to any address. The miner achieves this by including a special transaction in the block with exactly one transaction input and exactly one transaction output. The transaction input doesn’t reference any of the UTXOs. Instead, the reference has all of its bits set to zero, while the output index has all of its bits set to one. The miner chooses who can spend the transaction output by choosing the appropriate locking script. This special transaction is called the coinbase transaction.
The coinbase transaction must be the first transaction in each block.
The following table shows the structure of a regular transaction input.
| Size | Field | Description |
|---|---|---|
| 32 bytes | Transaction Hash | Reference to the transaction containing the UTXO to be spent |
| 4 bytes | Output Index | The index of the UTXO in the transaction to be spent (0-based) |
| 1-9 bytes (VarInt) | Unlocking Script Size | Unlocking-Script length in bytes |
| Variable | Unlocking Script | A script to unlock the UTXO’s locking script |
The following table shows the structure of a coinbase transaction input.
| Size | Field | Description |
|---|---|---|
| 32 bytes | Transaction Hash | All bits are zero (instead of a transaction reference) |
| 4 bytes | Output Index | All bits are ones, i.e., 0xFFFFFFFF (instead of the transaction output index) |
| 1-9 bytes (VarInt) | Coinbase Data Size | Length of the Coinbase Data in bytes |
| Variable | Coinbase Data | Arbitrary Data is used for the extra nonce and mining tags. Must begin with block height. |
Implement a coinbase transaction
Let’s introduce some helper methods to check if the transaction is a coinbase transaction.
// learncoin/src/transaction.rs
// Set all bits to 0.
const COINBASE_UTXO_ID: TransactionId = TransactionId(Sha256::new([0; 32]));
// Set all bits to 1.
const COINBASE_OUTPUT_INDEX: OutputIndex = OutputIndex::new(-1);
// ...
impl TransactionInput {
// ...
pub fn new_coinbase() -> Self {
Self {
utxo_id: COINBASE_UTXO_ID,
output_index: COINBASE_OUTPUT_INDEX,
}
}
pub fn is_coinbase(&self) -> bool {
self.utxo_id == COINBASE_UTXO_ID && self.output_index == COINBASE_OUTPUT_INDEX
}
}Let’s also introduce a function to validate the transaction format.
// learncoin/src/transaction.rs
impl Transaction {
// ...
pub fn new(
inputs: Vec<TransactionInput>,
outputs: Vec<TransactionOutput>,
) -> Result<Self, String> {
// ...
transaction.validate_format()?;
Ok(transaction)
}
/// Checks if the format of the transaction is valid, i.e.
/// Format is valid if any of the following are satisfied:
/// - A transaction contains no coinbase inputs
/// - A transaction contains exactly 1 coinbase input and exactly one output.
fn validate_format(&self) -> Result<(), String> {
let contains_coinbase_inputs = self.inputs.iter().any(TransactionInput::is_coinbase);
let coinbase_requirements_satisfied = self.inputs.len() == 1 && self.outputs.len() == 1;
if contains_coinbase_inputs && !coinbase_requirements_satisfied {
Err(format!("Transaction: {} has the coinbase input, but it doesn't satisfy all coinbase requirements.", self.id))
} else {
Ok(())
}
}
}We’ve changed the constructor’s signature because we cannot always trust the data to construct a transaction, e.g., when other network participants receive that data.
What is a miner?
We’ve talked about transactions in one of the previous blog posts. However, we didn’t discuss how these transactions are processed. The mining process serves two purposes:
- It verifies the transactions, which means that the transaction outputs are successfully transferred to another owner. Miners clear transactions by including them in the next mined block that satisfies certain criteria.
- It creates a new bitcoin in each block. The amount of bitcoin created per block is limited and diminishes with time.
New transactions are constantly flowing into the network (e.g., from user wallets). Upon receiving the transaction, the node adds it to the transaction pool. As the miner constructs the new block, it picks a subset (potentially all) of unverified transactions from the transaction pool. Then it searches for the solution that satisfies the difficulty target specified by the blockchain network.
If the miner finds the correct solution that matches the difficulty criteria, the block is mined. When a miner finds a block, it shares it with other nodes in the network. The network adds the block and its transactions to the blockchain, and we say the transaction has been verified.
Transactions have different levels of verification that we call confirmations. When the network accepts the block that includes the transaction, we say that the transaction is confirmed once. For each additional block in the blockchain, we say that the transaction has an extra confirmation. More confirmations imply higher certainty that the network cannot reverse the transaction.
Consensus algorithm
In one the previous posts, we’ve already mentioned that the blockchain is effectively a tree of blocks, where each block has a single parent but potentially multiple child blocks due to miners finding blocks simultaneously. The genesis block is the root of the blockchain tree, and each path from the root to a leaf is called a chain. The consensus algorithm is a process of deciding which chain is accepted by the network. The chain selected by the network is an active chain, while others are called non-active or secondary chains. The network always chooses the chain that requires the most mining work. In practice, that’s almost always the longer chain.
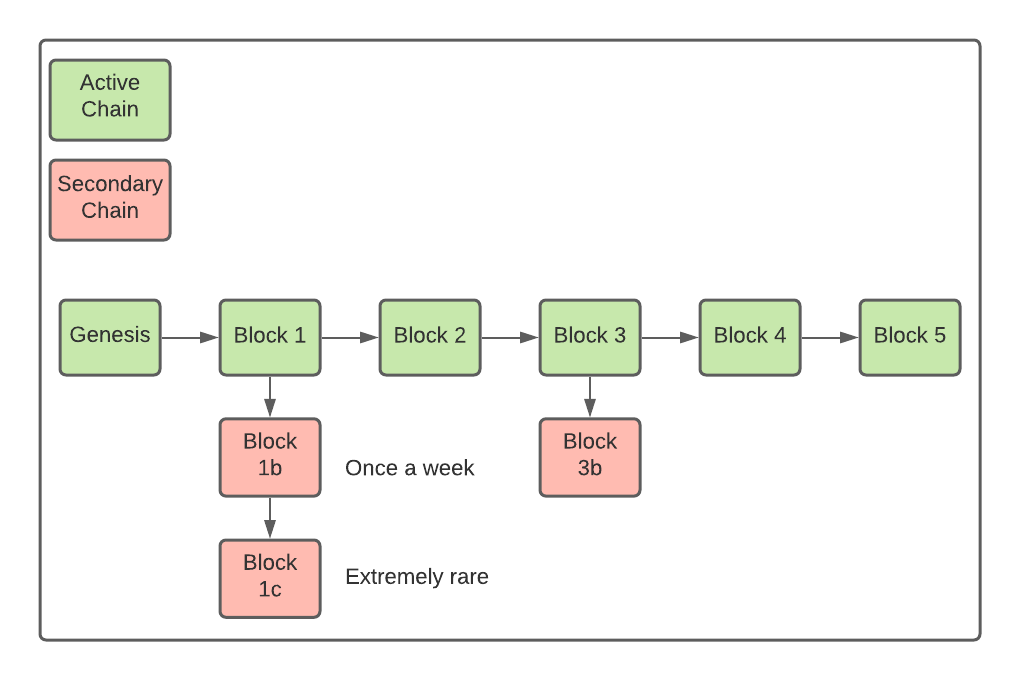
The above diagram shows the blockchain tree with the active and secondary chains, and how often the forks may appear.
It may happen that the nodes in the network temporarily disagree on what is the active chain because the total mining work is the same. However, one group of nodes will eventually find a new block, and when the block is propagated through the network, other groups will update their active chain, reaching the consensus.
You may wonder, but what if two groups keep on finding new blocks at the same time? While technically possible, the probability of that happening is too low. E.g., two blocks may be mined simultaneously once a week, but going a level deeper before reaching a consensus is exceedingly rare.
Let’s look at the following example to understand the consensus algorithm better.
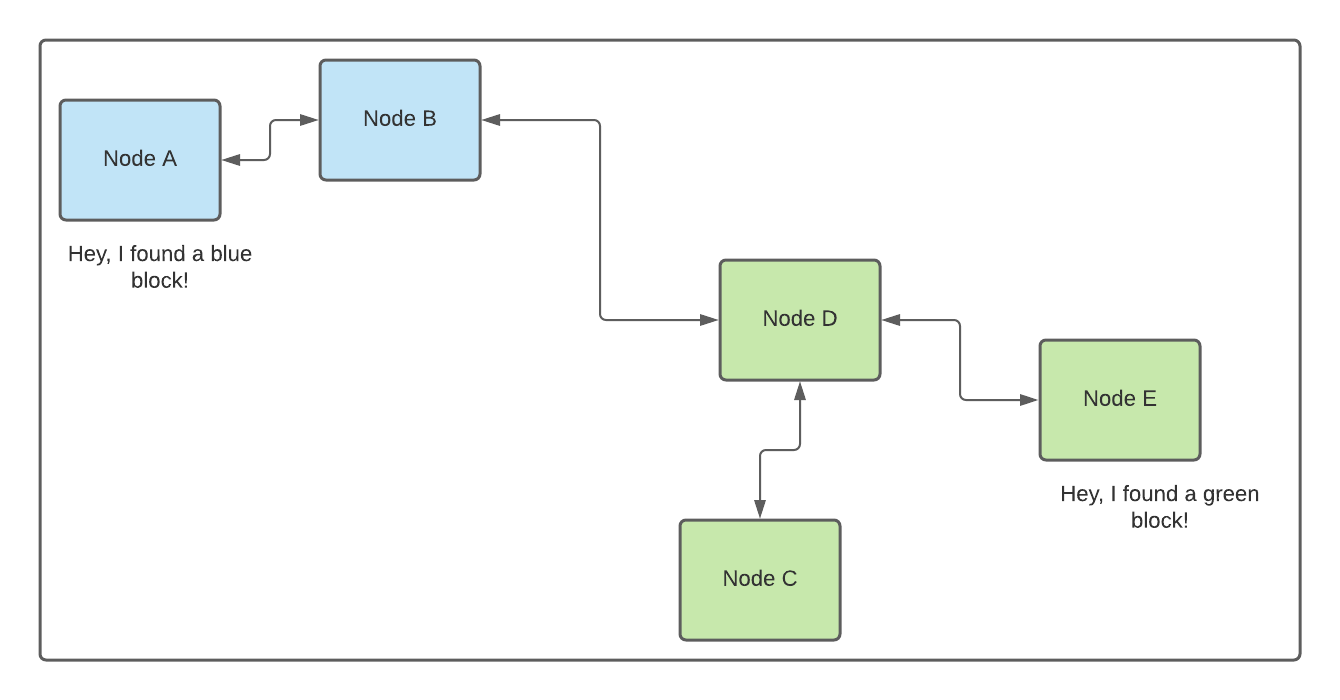
There are five nodes in the network called A, B, C, D, and E. They all have the same view of the blockchain initially and the same mining power. At some point, node A finds a block, let’s call it a blue block, and simultaneously node E finds another block. Let’s call it a green block. Each node propagates the new block to its peers, and eventually, we have the split as shown in the above diagram. The separation occurs because both blocks took the same amount of mining work.
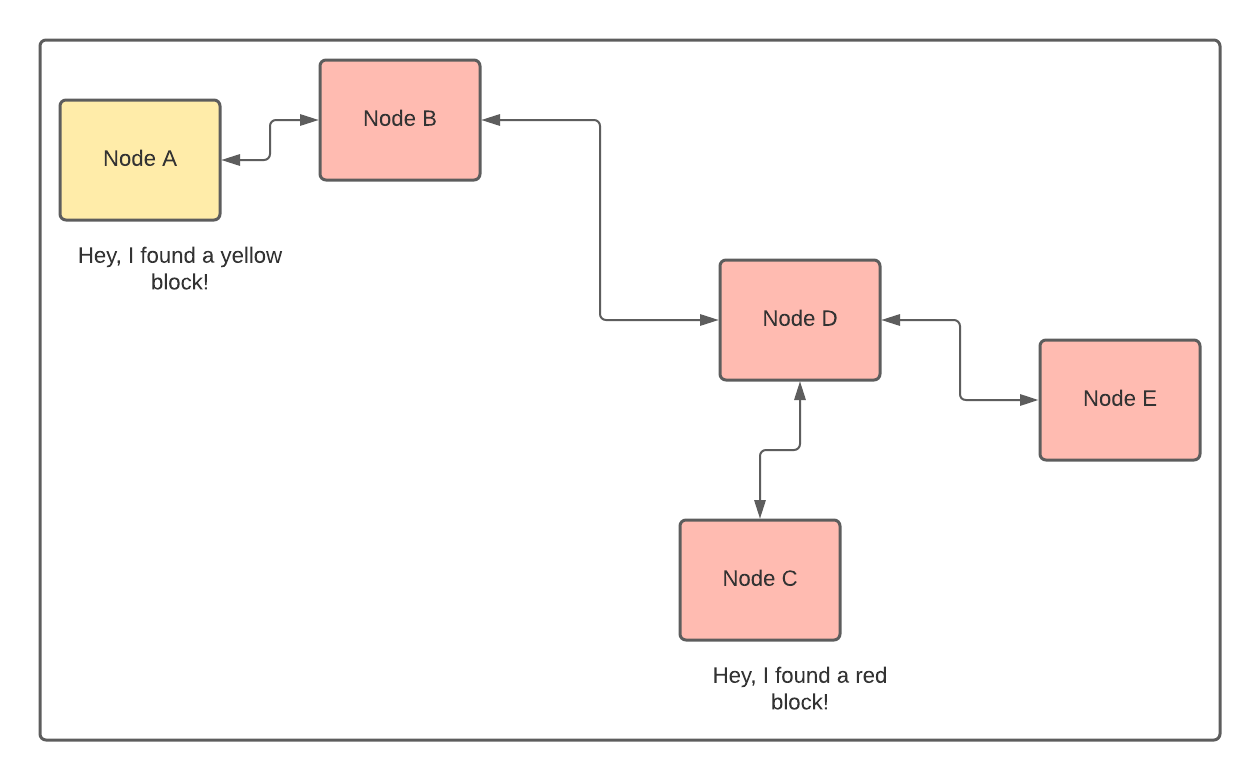
After some time, node C finds a new block. Let’s call it red block. It propagates the block to its peers, and its peers do the same. The block eventually reaches nodes B, C, D, and E, where node A finds a new block. Let’s call it yellow block.
The above scenario is improbable to happen, but let’s stick with it to see how it’s resolved. Four nodes believe the red block should be the tip of the active chain, and only one thinks it should be yellow. Four nodes are more likely to find the next block because they have four times more hashing power.
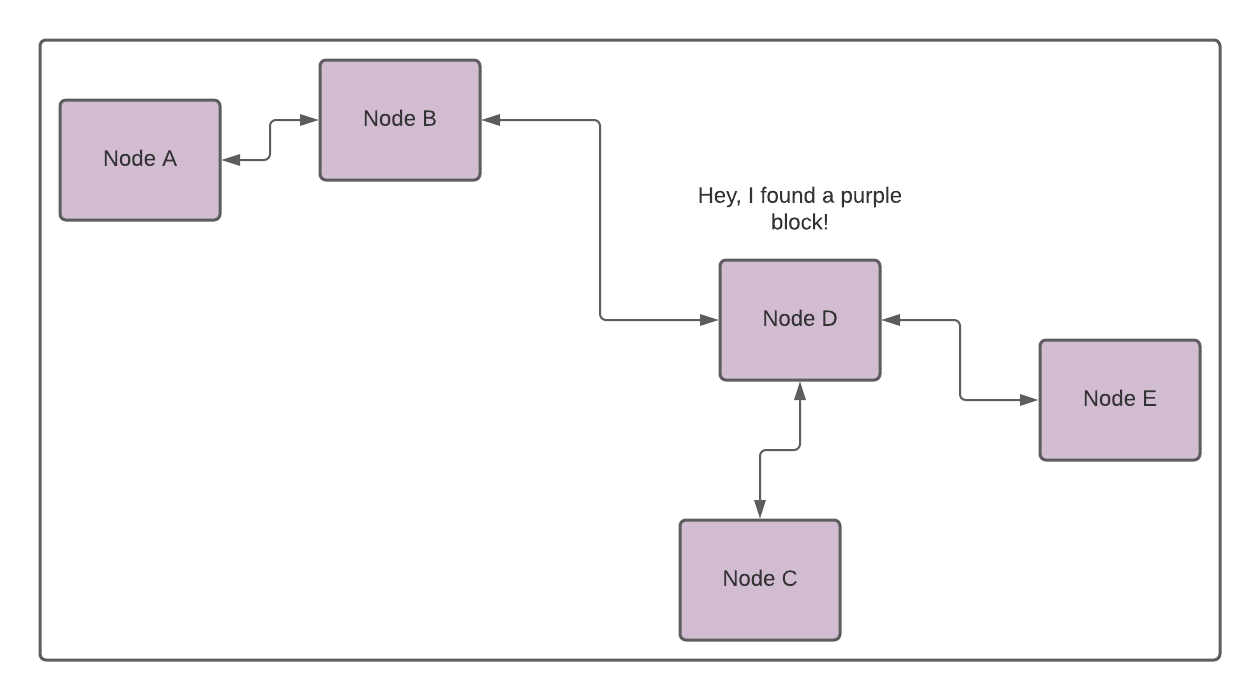
Node D finds the purple block, and the block is propagated through the whole network. Node A receives the purple block and updates its active chain because the purple block requires more mining power than the yellow block.
We will implement the consensus algorithm in one of the future blog posts.
Can transactions be reversed?
Transactions may be reversed when miners mine two blocks simultaneously. The transactions from the block that is dropped are not valid anymore, while the transactions from the block that made it into the active chain are kept.
Because two blocks may be mined simultaneously, the transactions should be confirmed more than once to have higher confidence that they are successful. The probability of a transaction being reversed drops exponentially with every confirmation, and six or more confirmations is considered sufficient proof that a transaction cannot be reversed.
Implement a proof of work algorithm
Before we implement the proof of work algorithm, let’s start with a function that calculates the target hash given the difficulty target. We’ve said that the difficulty target represents the number of leading zero bits in the resulting 256-bit hash.
// learncoin/src/proof_of_work.rs
impl ProofOfWork {
/// In practice, the target hash is calculated in a more complex way:
/// https://en.bitcoin.it/wiki/Difficulty
/// However, for learning purposes, we are going to implement a simpler version which
/// returns a hash with the first `difficulty` bits set to 0, and the rest set to 1.
fn target_hash(n_leading_zero_bits: u32) -> BlockHash {
let mut hash = [0xff; 32];
// Each byte has 8 bits, so we count how many chunks of 8 bits should be set to 0.
let num_zero_bytes = (n_leading_zero_bits / 8) as usize;
for i in 0..num_zero_bytes {
hash[i] = 0;
}
// Represents the number of least significant bits that are ones in the next byte.
let n_trailing_one_bits = 8 - (n_leading_zero_bits % 8);
// The special case is required to properly handle overflows, even though mathematically
// the below algorithm works.
// For example, 8 ones is 256, and the byte (u8) represents the values from: [0..255].
if n_trailing_one_bits == 8 {
return BlockHash::new(Sha256::from_raw(hash));
}
// Let's assume that `n_trailing_one_bits` is 5. We want to set the next byte to `00011111`.
// 2^n_trailing_one_bits is: `00100000`, i.e. `b00100000 - b1 = b00011111`.
hash[num_zero_bytes] = (1 << n_trailing_one_bits) - 1;
BlockHash::new(Sha256::from_raw(hash))
}
}Now that we know how to calculate the target hash for the given difficulty, the next step is to find a block hash less than or equal to the given difficulty target.
The algorithm computes the hash for each nonce value in the range [0, u32::MAX] and returns the nonce that satisfies the criteria.
// learncoin/src/proof_of_work.rs
impl ProofOfWork {
// ...
/// Returns the nonce such that the corresponding block hash meets the difficulty requirements,
/// i.e. the block hash is less than or equal to the target hash.
/// The function returns None if such nonce doesn't exist.
///
/// The target hash is calculated such that all values starting with `difficulty` number of
/// zeroes satisfy the difficulty requirements.
/// For example, if the difficulty is 5, the numbers (in binary format) starting with 5 zeros
/// satisfy the criteria.
pub fn compute_nonce(
previous_block_hash: &BlockHash,
merkle_root: &MerkleHash,
timestamp: u32,
difficulty: u32,
) -> Option<u32> {
let target_hash = Self::target_hash(difficulty);
let mut nonce = 0 as u32;
loop {
let block_header = BlockHeader::new(
previous_block_hash.clone(),
merkle_root.clone(),
timestamp,
difficulty,
nonce,
);
if Self::check_difficulty_criteria(&block_header, &target_hash) {
return Some(nonce);
}
if nonce == u32::MAX {
// We have run out of nonce values, stop the computation.
break;
}
nonce += 1;
}
None
}
}We are making significant progress! The only remaining detail is to implement the check_difficulty_criteria function. This function checks if the block hash is less than or equal to the target hash.
// learncoin/src/proof_of_work.rs
impl ProofOfWork {
// ...
/// Checks whether the given block header is less than or equal to the given target hash.
fn check_difficulty_criteria(block_header: &BlockHeader, target_hash: &BlockHash) -> bool {
match block_header.hash().cmp(target_hash) {
Ordering::Less | Ordering::Equal => true,
Ordering::Greater => false,
}
}
}The code in this chapter is complex enough that I ran into some difficulties getting all the nitty-gritty details right the first time, so I decided to write some tests.
Try to write a unit test that mines many different blocks and calculates the probability to mine a block.
The expected probability is 2^(256-difficulty) / 2^256 = ½^difficulty.
As a convenience, you can use the timestamp to generate different blocks.
In my test, the actual and expected values are very similar but not the same. However, the results are expected. The probability would be the same only if we test an infinite number of blocks. I’m happy with the current results, so I’ll leave it at that.
Actual: 0.00786582661735947. Expected: 0.0078125
thread 'proof_of_work::tests::probability_test' panicked at 'assertion failed: actual_probability == expected_probability', src\proof_of_work.rs:160:9Therefore, we are going to assert that the relative error is less than 1%.
// learncoin/src/proof_of_work.rs
#[test]
fn probability_test() {
const DIFFICULTY: u32 = 7;
const NUM_MINED_BLOCKS: u64 = 500_000;
let expected_probability: f64 = 1.0 / (2.0 as f64).powf(DIFFICULTY as f64);
let previous_block_hash = BlockHash::new(Sha256::from_raw([0; 32]));
let merkle_root = MerkleTree::merkle_root_from_transactions(&create_transactions());
let mut total_nonces = 0 as u64;
// We are using a timestamp to modify the block header, and ensure its block hash is
// different from block hashes of other blocks in this test.
for timestamp in 0..(NUM_MINED_BLOCKS as u32) {
let nonce = ProofOfWork::compute_nonce(
&previous_block_hash,
&merkle_root,
timestamp,
DIFFICULTY,
)
.unwrap();
total_nonces += nonce as u64;
}
let actual_probability = (NUM_MINED_BLOCKS as f64) / (total_nonces as f64);
// Assert that the relative error is less than 1%.
assert!((expected_probability - actual_probability) / expected_probability < 0.01);
}I’ve also added some additional testing to make sure that proof of work satisfies the difficulty criteria. Furthermore, I decided to add a benchmark to see how many hashes per second the proof of work implementation can test. It’s about 1M on my machine. You can find the benchmark implementation here.
What if the solution doesn’t exist?
You may wonder if 2^32 nonce values are always enough to find a solution. No, it’s not. Nowadays, it takes a lot more attempts until a miner finds the answer. In the past, miners have tweaked the timestamp a bit when they run out of nonce values. However, when the hash power increased, tweaking timestamps was no longer a feasible solution since it would go beyond the allowed limit. The timestamp associated with the block must not be more than 2 hours apart from the node’s local time.
Remember how the coinbase transaction has coinbase data instead of the unlocking script? The miner can set the coinbase data to any value and use it as an extra nonce. The extra nonce is quite extensive, and it’s unlikely that the miner can have such hashing power that it runs out of different block hash options before finding a solution.
We will not use the extra nonce in our initial implementation, but this is a good exercise for you. Go ahead and try to extend the proof of work algorithm such that it updates the extra nonce when it runs out of regular nonce values.
Summary
Hopefully, the topics covered in this post were interesting to you. To summarize what we did:
- We understand what Proof of Work and difficulty are and we have written code to showcase that.
- We understand the role of a Miner and Coinbase tranasctions.
- We implemented a probability test to mine blocks.
- We implemented a benchmark to get a better sense of the hash power that our PoW algorithm can reach in a given platform.
- We learned about active and secondary chains.
- We explained how a consensus algorithm to agree on the active chain works.
Here’s the full source code.
What’s next?
In the next post, we will talk about a peer-to-peer network and implement communication between the nodes in the LearnCoin network.
Enjoyed this post?
I send an email every two weeks about computer science and software engineering. No fluff, no hype — just the mechanism behind the things we use every day.